引言

OpenClaw是最近火爆的个人开源智能体框架。由于它具备本地自托管、长期记忆、丰富技能SKILLs等优势,让它在github上迅速收获了$248 K^+$stars。
然而由于它实现的任务的前提是大量的token开销,所以如果能结合本地模型使用,将节省很大一笔花费。得益于Ollama的支持和Qwen推出的最新小尺寸、高性能3.5系列模型,让OpenClaw本地的高效使用得以成为现实。
本文从实验室服务器配置OC的角度出发,以没有root权限指令受限为前提,记录从零一步步搭建起属于自己的本地AI助手。相关项目仓库连接如下:
OpenClaw
┌──────────────────────┐
│ 各种聊天平台 │
│ WhatsApp / Telegram │
│ Discord / Slack / ...│
└──────────┬───────────┘
│
▼
┌─────────────────────────────┐
│ Channel Adapters │ ← 消息解析 + 鉴权 + 格式化
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ GATEWAY │ ← 控制中枢(WebSocket:18789)
│ • 会话路由 │
│ • 访问控制(配对/白名单) │
│ • 事件分发 │
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ Agent Runtime │ ← ReAct 循环(Pi 核心)
│ 1. 组装上下文(历史 + 记忆)│
│ 2. 调用 LLM(流式) │
│ 3. 拦截工具调用 │
│ 4. 执行工具(沙箱) │
│ 5. 持久化状态 → 继续循环 │
└──────────────┬──────────────┘
│
┌─────────────┴─────────────┐
│ │
▼ ▼
LLM 智能决策 工具执行层
(Claude / GPT / 本地模型) (浏览器 / 文件 / 邮件 / cron / 技能)
│ │
└─────────────┬─────────────┘
▼
结果返回给用户
几个重要的文件:
/workspace/
├── SOUL.md 👤 我的核心价值观
├── IDENTITY.md 🎭 我的身份设定
├── USER.md 👨 关于你的信息
├── TOOLS.md 🔧 我的工具配置
├── AGENTS.md 📚 操作指南
├── HEARTBEAT.md 💓 定期任务
├── BOOTSTRAP.md 🚀 初始化(待删除)
├── memory/ 📖 每日日志
└── logs/ 📊 运行日志
- TOOLS.md
- 专属工具配置和环境信息,记录所有不共享的本地配置。常用工具如:搜索信息。
- SOUL.md
- 核心原则:
- ✅ 真诚助人,不说废话
- ✅ 可以有观点和个性
- ✅ 先尝试解决,再提问
- ✅ 通过能力赢得信任
- ✅ 尊重隐私边界
- 关键规则:
- 私人信息绝不外泄
- 外部行动前需确认
- 群聊中保持适度参与
- 核心原则:
- IDENTITY.md
- 当前设定:
- 名字: Jarvis
- 角色: 私人助理 + 情报搜集官
- 风格: 专业但亲切,高效但不死板
- 语言: 中文
- emoji: 👔
- 当前设定:
- USER.md
- 当前记录:
- 称呼: boss
- 时区: Asia/Shanghai
- 需求: 高效的支持和情报服务
- 待补充: 你的名字和更多偏好
- 当前记录:
- AGENTS.md
- 📝 记忆管理: MEMORY.md(长期)+ memory/YYYY-MM-DD.md(每日)
- 🔄 定时检查: Heartbeat(~30 分钟)vs Cron(精确时间)
- 💬 群聊规则: 何时发言、何时静音、何时用反应
- 🔧 工具使用: Skills 技能框架
- 🛡️ 安全规范: 外部行动需确认
- HEARTBEAT.md
- 定期检查事项清单
- BOOTSTRAP.md
- 首次启动时的引导流程。
配置流程
配置GO
cd /tmp
wget https://go.dev/dl/go1.26.0.linux-amd64.tar.gz
mkdir -p ~/opt
tar -C ~/opt -xzf go1.26.0.linux-amd64.tar.gz
cat >> ~/.bashrc << 'EOF'
export GOROOT=$HOME/opt/go
export GOPATH=$HOME/go
export PATH=$GOROOT/bin:$GOPATH/bin:$HOME/.local/bin:$PATH
export GOPROXY=https://goproxy.cn,direct
export GOTOOLCHAIN=local
EOF
source ~/.bashrc
go version
安装CMake
cd /tmp
wget https://github.com/Kitware/CMake/releases/download/v4.2.3/cmake-4.2.3-linux-x86_64.tar.gz
# 大部分情况下需要代理,代理指令如下:
# wget https://ghproxy.net/https://github.com/Kitware/CMake/releases/download/v4.2.3/cmake-4.2.3-linux-x86_64.tar.gz
tar -C ~/opt -xzf cmake-4.2.3-linux-x86_64.tar.gz
cat >> ~/.bashrc << 'EOF'
export PATH=$HOME/opt/cmake-4.2.3-linux-x86_64/bin:$PATH
EOF
source ~/.bashrc
cmake --version
确保GPU条件
nvidia-smi
ls /usr/local/cuda
nvcc --version
(可选)安装NVCC
conda create -n ollama-gpu python=3.11 -y
conda activate ollama-gpu
# 核心命令:指定 label/cuda-12.8.0 子频道
conda install -y cuda-toolkit -c nvidia/label/cuda-12.8.0
# 如果上面失败或想更完整,安装 cuda 包(包含 toolkit + runtime)
# conda install -y cuda -c nvidia/label/cuda-12.8.0
conda install -y cuda-nvcc cuda-cudart-dev cuda-libraries-dev -c nvidia/label/cuda-12.8.0
cat >> ~/.bashrc << 'EOF'
# CUDA from Conda (ollama-gpu env)
export CUDA_HOME=$HOME/miniconda/envs/ollama-gpu
# 替换成你的 conda prefix,如果不是 ~/miniconda
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib:$LD_LIBRARY_PATH
export CUDACXX=$CUDA_HOME/bin/nvcc
EOF
source ~/.bashrc
# 验证
conda activate ollama-gpu
nvcc --version
源码编译Ollama
cmake -B build \
-DLLAMA_CUDA=ON \
-DCMAKE_CUDA_COMPILER=$CUDACXX \
-DCMAKE_CUDA_ARCHITECTURES="80" # 替换成你的 GPU arch(nvidia-smi -L 查看型号,A100=80, RTX 30xx=86, RTX 40xx=89 等)
cmake --build build -j$(nproc)
go build -o ~/.local/bin/ollama .
cp -r build/lib/ollama/* ~/.local/lib/ollama/
编译加速库(llama.cpp 部分)
# 直接运行(cmake 已生成 build 文件):
cmake --build build -j$(nproc)
# -j 用所有核心加速,第一次可能 5-15 分钟
编译 Ollama 主程序(Go 部分)
go build -o ~/.local/bin/ollama .
复制 CUDA 加速库到用户目录
mkdir -p ~/.local/lib/ollama
cp -r build/lib/ollama/* ~/.local/lib/ollama/ 2>/dev/null || true
确保环境变量包含 CUDA & Ollama lib
cat >> ~/.bashrc << 'EOF'
# CUDA from Conda env
export PATH="$HOME/miniconda3/envs/cuda12/bin:$PATH"
export LD_LIBRARY_PATH="$HOME/miniconda3/envs/cuda12/lib:$HOME/.local/lib/ollama:$LD_LIBRARY_PATH"
export CUDACXX="$HOME/miniconda3/envs/cuda12/bin/nvcc"
EOF
source ~/.bashrc
安装OpenClaw
ollama launch openclaw
- Install — If OpenClaw isn’t installed, Ollama prompts to install it via npm
- Security — On the first launch, a security notice explains the risks of tool access
- Model — Pick a model from the selector (local or cloud)
- Onboarding — Ollama configures the provider, installs the gateway daemon, and sets your model as the primary
- Gateway — Starts in the background and opens the OpenClaw TUI
简而言之,使用上述指令,ollama会帮你完成每一步需要配置的过程,开箱即用。
结果展示
使用中,Qwen3.5-27b表现很亮眼,尤其我之前配置的是Qwen2.5-72B-Instruct-AWQ,结果连构造Terminal查询指令都难以一次完成。新的模型在指令跟随和简单任务完成上做的很好:
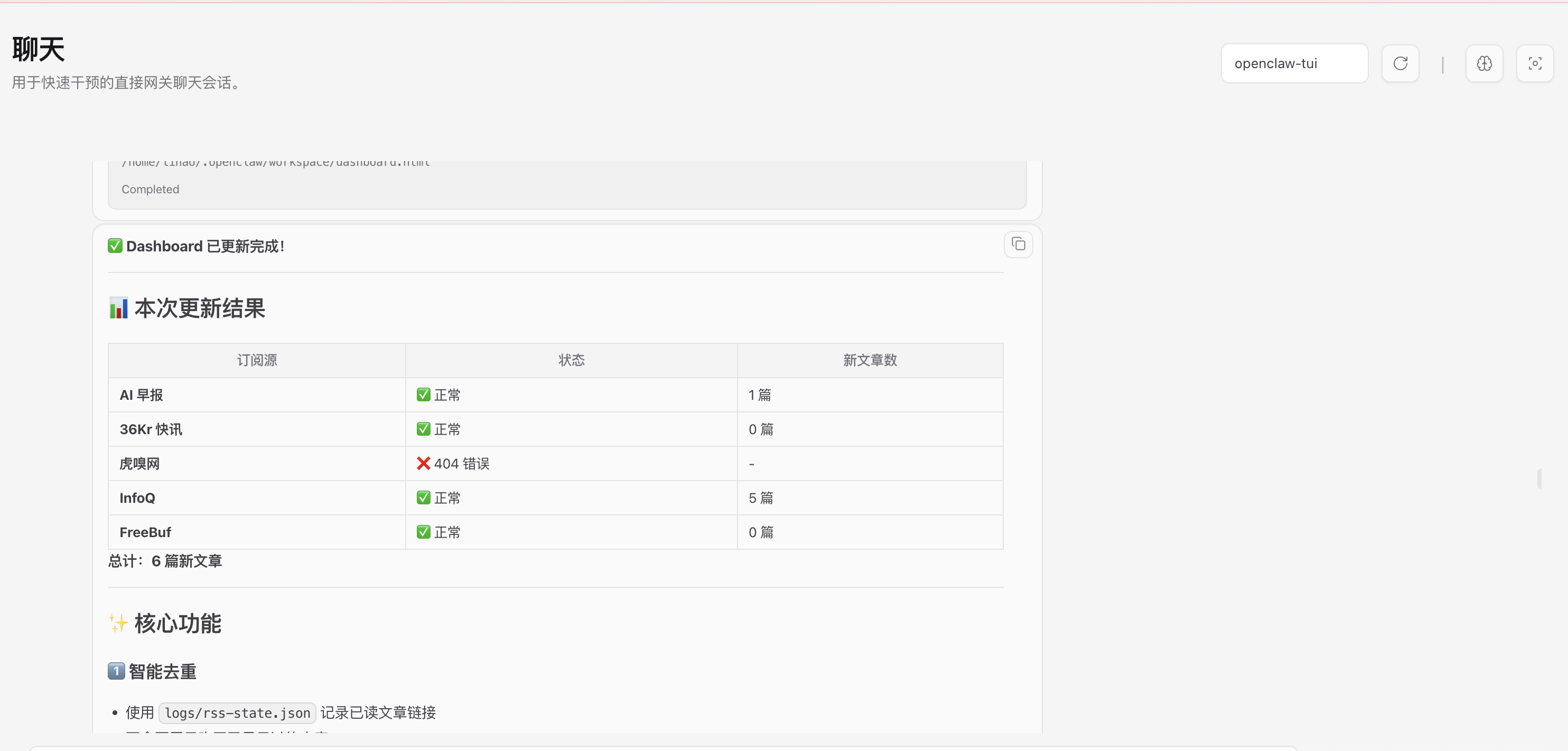
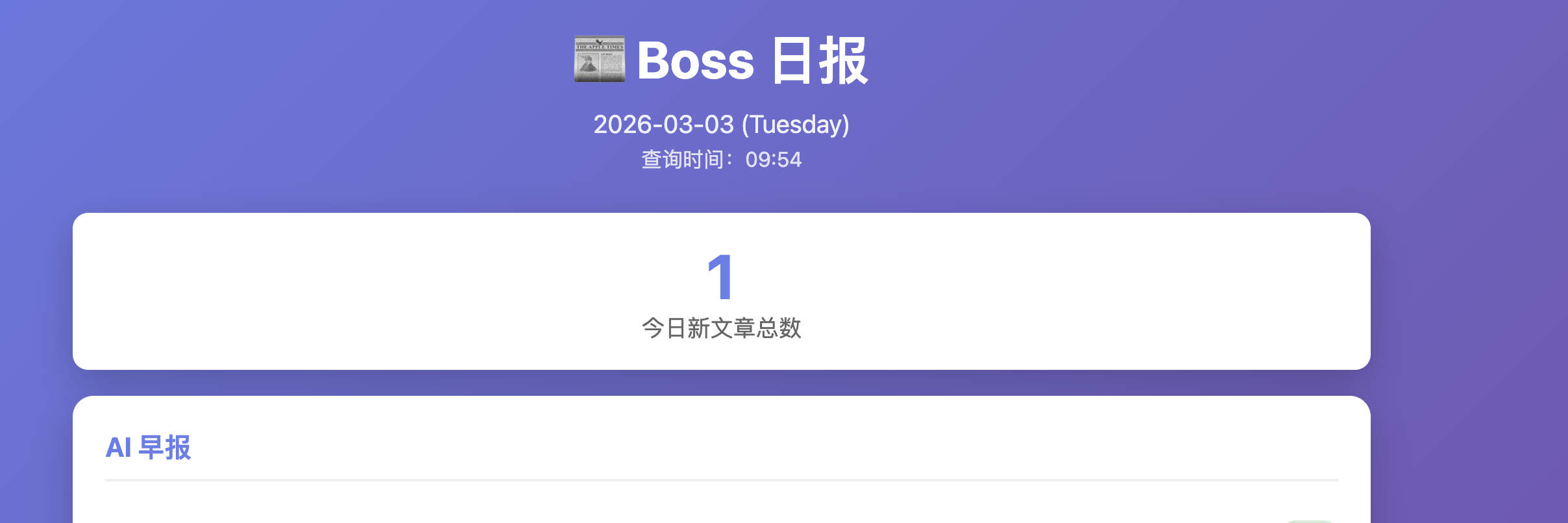
可以更进一步,让它设计一个网页去展示获取的信息:
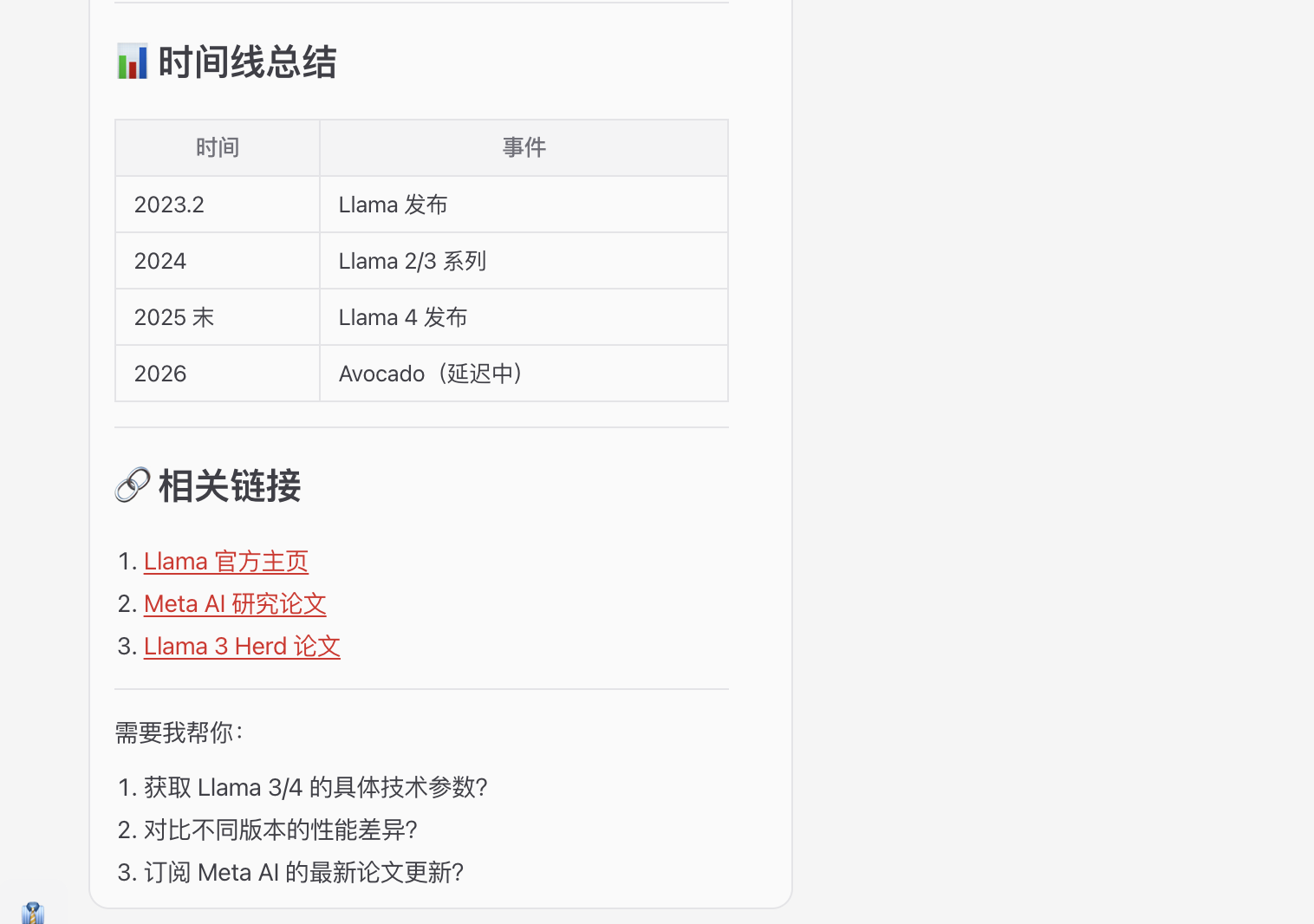
同样,配置搜索功能后也可以去获取论文、博客等数据并总结给你:
而且,得益于Ollama的keep-alive功能,可以持续在后台运行,当一段时间没有输入时,自动卸载显存占用,不会导致实验室的显卡被长久占住:
推荐结合tmux指令运行,如下:
tmux new-session -s oc
tmux split-window -h
ctrl b <-/->
校园网环境下如何在不打开vscode的情况下优雅地访问WebUI:
ssh -N \
-L port:127.0.0.1:port \
-L xxx \
user@ip
如何卸载?
openclaw uninstall --all --yes --non-interactive
# 或者直接移除下列目录:
~/.openclaw
总结
是一个非常有意思的工具,虽然在精细任务上无法与现有的大厂Agent进行抗衡,但是在情绪价值(精准记住你的各种信息)、粗粒度任务(日常情报搜集)、扩展任务(未来可以尝试接入通讯工具实现宣传的手机指挥工作)等方面都非常亮眼。让人感慨,《钢铁侠》中的AI助手Jarvis或许在有生之年就可以实现。
