摘要
- 项目介绍:包含用于生成式智能体(一种能够模拟逼真人类行为的计算智能体)的核心模拟模块及其游戏环境。以下将详细介绍如何在本地计算机上设置模拟环境,以及如何将模拟结果以演示动画的形式回放。
- 项目参考:
- 主要目标:
- 理解项目代码及运行原理
- 修改为vLLM支持并设置本地的LLMs和embedding 模型
- 相关复现代码
运行环境配置及vLLM支持
- 拷贝项目并创建环境
git clone https://github.com/x-glacier/GenerativeAgentsCN.git
cd GenerativeAgentsCN
conda create -n generative_agents_cn python=3.12
conda activate generative_agents_cn
pip install -U uv
uv pip install -r requirements.txt
- 启动运行(默认项目启动方式)
cd generative_agents
python start.py --name sim-test --start "20250213-09:30" --step 10 --stride 10
- 参数说明:
- name: 每次启动虚拟小镇,需要设定唯一的名称,用于事后回放。
- start: 虚拟小镇的起始时间。
- resume: 在运行结束或意外中断后,从上次的“断点”处,继续运行虚拟小镇。
- step: 在迭代多少步之后停止运行。
- stride: 每一步迭代在虚拟小镇中对应的时间(分钟)。假如设定–stride 10,虚拟小镇在迭代过程中的时间变化将会是 9:00,9:10,9:20 …
- 修改
LLMs和embedding model的位置:generative_agents/data/config.json replay:python replay.py- 默认端口为
5000,若需要修改,进入replay中设置app.run(debug=True,port=5050) - 可以追加的参数:
name、step、speed、zoom
- 默认端口为
compress:python compress.py --name <simulation-name>- 运行结束后将在
results/compressed/<simulation-name>目录下生成回放数据文件movement.json。同时还将生成simulation.md,以时间线方式呈现每个智能体的状态及对话内容
- 运行结束后将在
- 启动运行(使用vLLM进行推理)
- 模型和embedding配置依旧在
generative_agents/data/config.json - 先使用指令启动vLLM服务(
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-7B-Instruct) - 进入新的终端启动原始的项目:
cd generative_agents->python start.py --name <simulation-name> - 程序现在将连接到本地运行的 VLLM 服务,并使用本地的 Hugging Face 模型进行模拟。后续的
compress.py和replay.py操作与之前完全相同。 - 注意:启动的vLLM的模型名与
config.json中的模型名应一致,如都为:Qwen/Qwen2.5-7B-Instruct
- 模型和embedding配置依旧在
- 修改vLLM以支持:
generative_agents/modules/model/llm_model.py- 使其能够识别并处理
vllm提供者(复用 OpenAI 兼容接口)。
- 使其能够识别并处理
- 修改embedding以支持:
generative_agents/modules/storage/index.py- 无需改动;
结果展示:
vLLM配置结果如下(首次启动需要下载模型):
再次启动时速度会显著加快:
启动项目情况如下(同理启动时需要经过embedding,需要等待一定时间):
结束时的总结输出:
使用replay回顾过程:

代码分析
核心机制解析
项目通过 LlamaIndex 实现向量化的记忆存储和检索,通过精心设计的 prompt 链(Prompts Chaining)来引导 LLM 完成反思和规划等高级认知任务,实现论文中的核心功能。
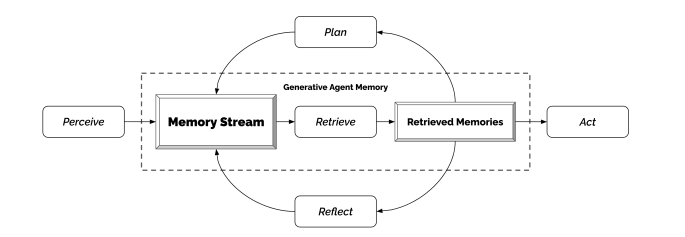
记忆流 (Memory Stream)
- 描述:记忆流是智能体所有经验的完整记录,它将每一个事件、观察或想法都作为一个“记忆”对象存储起来。当智能体需要行动时,它会从记忆流中检索相关的记忆。检索机制综合考虑了三个因素:
- 新近度 (Recency): 最近发生的事件得分更高。
- 重要性 (Importance): 智能体认为更重要的事件得分更高(由 LLM 直接打分)。
- 相关性 (Relevance): 与当前情境更相关的事件得分更高(通过 embedding 相似度计算)。
- 代码位置:
generative_agents/modules/memory/associate.py- 记忆的存储:
- 智能体的所有记忆(事件、想法、对话)都封装在 Concept 对象中,并存储在由LlamaIndex管理的向量数据库里。这在 Associate.add_node() 方法中实现。
- 每次添加记忆时,除了记录事件本身,还会记录其 poignancy (重要性分数)、创建时间 create和访问时间 access。
- 记忆的检索 (Retrieval):
- 项目中最能体现论文思想的是 AssociateRetriever类。当需要检索记忆时,这个类会计算每个记忆节点的最终得分。
- 在 _retrieve 方法中,它精确地实现了论文中的三大评分标准:
- 新近度 (Recency) 分数:基于最后访问时间进行排序,并使用指数衰减函数计算分数
- 相关性 (Relevance) 分数:来自向量检索的原始相似度分数
- 重要性 (Importance) 分数:直接使用记忆中的 “poignancy” 字段
- 记忆的存储:
反思 (Reflection)
-
描述:当智能体积累了足够多的经验后,它会暂停下来进行“反思”。反思是一个更高层次的思考过程,智能体会回顾最近的记忆,提出一些关于自己的关键问题,并尝试回答这些问题,从而形成更抽象、更高层次的“洞见”(Insight)。这个洞见也会被存入记忆流。反思的触发时机是当最近的记忆重要性分数之和超过一个阈值时。
-
代码位置:
generative_agents/modules/agent.py的think方法中,并利用了generative_agents/data/prompts/目录下的多个 prompt 文件;- 触发时机:在
Agent.think方法中,系统会检查智能体自上次反思以来,新产生的记忆的poignancy(重要性)总和是否超过了阈值poignancy_max(在 config.json 中配置,默认为 150) - 反思过程 (
_reflect()方法):- 第一步:确定反思主题。程序会调用 LLM,让它阅读最近的 100 条记忆,并提出 3个最值得思考的高层次问题。这是通过
reflect_focus.txt这个 prompt 实现的。它会引导 LLM 生成问题。 - 第二步:生成洞见 (
reflect_insights.txt)。程序会遍历上一步生成的每个问题,然后:- 使用该问题作为关键词,再次从记忆流中检索相关的记忆片段(事件、想法等)。
- 将这些相关的记忆片段和问题一起提交给 LLM,让 LLM根据这些材料进行总结,并得出结论(即“洞见”)。
- 这是通过
reflect_insights.txt这个 prompt 实现的。
- 第三步:存储洞见。生成的“洞见”会被赋予一个较高的重要性分数,然后像普通记忆一样被存入记忆流中,供未来检索和规划使用。
- 第一步:确定反思主题。程序会调用 LLM,让它阅读最近的 100 条记忆,并提出 3个最值得思考的高层次问题。这是通过
- 触发时机:在
规划 (Planning)
- 描述:规划赋予智能体长期目标和执行能力。智能体的规划是分层进行的:
- 长期规划: 每天早上,智能体根据自己的身份、性格和过去的经验,制定一个当天的粗略计划(例如,“写一本书”、“练习吉他”)。
- 短期规划: 智能体将长期计划分解成具体的行动步骤(例如,早上 9 点去书房,10点开始写作…),并按时间顺序执行。
- 动态调整: 智能体在执行计划时,会根据当前的环境和他人的互动,动态地调整或中断自己的计划。
- 代码位置:
generative_agents/modules/agent.py和generative_agents/modules/memory/schedule.py共同完成;- 生成日度计划 (
schedule_daily方法):- 在智能体“醒来”时(
_wake_up方法),会调用_schedule_daily()。 - 该方法使用
schedule_daily.txt这个prompt,将智能体的基本信息(姓名、性格、最近的总结)和前一天的总结作为输入,要求 LLM生成一份当天的总体计划(以小时为单位)。
- 在智能体“醒来”时(
- 计划分解 (
_decompose_schedule()方法):- 当智能体需要决定接下来一两个小时做什么时,它会调用 decompose 方法。
- 该方法使用
schedule_decompose.txt这个 prompt,将日度计划中当前时间段的任务(例如,“9am:go to the library to write a book”)作为输入,要求 LLM 将其分解为更精细的、以 5-15分钟为单位的行动序列。
- 计划存储和管理:
- 所有生成的计划和行动都存储在 Schedule 对象中(定义在
schedule.py)。这个对象负责跟踪每个任务的状态(未开始、进行中、已完成)。 - Agent 对象持有一个 _schedule 成员变量,在每个时间步(
_act方法)都会检查当前的计划,并决定是继续当前行动、开始新行动还是对环境做出反应。
- 所有生成的计划和行动都存储在 Schedule 对象中(定义在
- 重新规划/反应 (
_revise_schedule和_react方法):- 当智能体观察到某个重要事件时(例如,有人和它打招呼),
_react方法会被触发(用于响应外部事件)。 - 系统会判断当前事件是否重要到需要中断当前计划。如果需要,它可能会调用
_revise_schedule方法(用于修正计划),并使用schedule_revise.txtprompt 来更新或调整后续的计划。
- 当智能体观察到某个重要事件时(例如,有人和它打招呼),
- 生成日度计划 (
总结
ZJU在这篇论文的基础上,发布了一个关于基于LLM的自适应社会仿真微核多智能体系统框架。和这个工作的区别为:
- 实现一个分布式系统,只是“节点”不再是传统服务,而是大量自治的智能体(agents)。即一个以“多智能体”为工作负载的、事件驱动的分布式系统(distributed multi-agent system infrastructure)
- Agent-Kernel 的关键在于:并行的是“决策”,而不是“世界修改权”。agent 是 无写权限的 worker,Kernel 是 唯一有世界写权限的 authority,即主从式(master–worker)分布式架构
- 从
Agent 直接修改世界状态变为Agent → 提交 Action Proposal=>System → 校验 → 执行 / 拒绝
| GenerativeAgentsCN | Agent-Kernel 风格 |
|---|---|
| 世界状态 = Python 对象 | 世界状态 = 共享状态 / 状态服务 |
| agent 直接写 | agent 通过协议请求修改 |
| 默认强一致 | 可配置一致性模型 |
一个总结对比:
- 🤖generative_agents:
for step in simulation:
for agent in agents:
agent.observe()
agent.think()
agent.act() # 直接改世界
- 🤖Agent-Kernel
[事件] 时间 +1
↓
Kernel 判断哪些 agent 需要响应
↓
把 3,000 个 agent 的“决策任务”
分发到不同机器并行执行
↓
Agent_i → 生成 action proposal
↓
Kernel 校验 → 更新世界