引言
使用 Unsloth 进行多 GPU 训练 参考官方发布的公告,本篇博客意在测试unsloth的多卡训练的情况。
同时,也有开源项目实现了更为简便的并行操作,如: opensloth。
大致介绍unsloth: Unsloth 是一个面向大语言模型(LLM)训练与微调的高效框架,核心目标是——让用户在极低显存下高效地训练或微调大模型。它主要针对个人研究者、小规模 GPU 环境进行了大量优化。
- 极致显存优化(Ultra-Memory Efficient): 如支持 4bit / 8bit 量化加载(QLoRA 技术)
- 高性能实现(Fast Runtime):对 Hugging Face transformers 的 Trainer 做底层优化。内置 CUDA 加速算子,支持 FlashAttention、PagedAttention 等。实际训练速度通常比原生 HF 微调快 2–5 倍。
- 简洁易用的接口(Simple API):主体函数 FastLanguageModel.from_pretrained() 与 Hugging Face 接口保持一致
- 多种支持:支持 PEFT / LoRA / QLoRA、分布式与多 GPU 支持(Distributed Ready)、兼容 Hugging Face 模型与 tokenizer等;
环境说明
本次测试的环境搭建主要依托unsloth框架。
安装指导:
pip install --upgrade unsloth
pip show unsloth,结果如下:
Name: unsloth
Version: 2025.11.2
Summary: 2-5X faster training, reinforcement learning & finetuning
Home-page: http://www.unsloth.ai
Author: Unsloth AI team
Author-email: info@unsloth.ai
License-Expression: Apache-2.0
Location: /home/lihao/miniconda3/envs/unsloth_upgrade/lib/python3.11/site-packages
Requires: accelerate, bitsandbytes, datasets, diffusers, hf_transfer, huggingface_hub, numpy, packaging, peft, protobuf, psutil, sentencepiece, torch, torchvision, tqdm, transformers, triton, trl, tyro, unsloth_zoo, wheel, xformers
Required-by:
pip show accelerate结果如下:
Name: accelerate
Version: 1.5.2
Summary: Accelerate
Home-page: https://github.com/huggingface/accelerate
Author: The HuggingFace team
Author-email: zach.mueller@huggingface.co
License: Apache
Location: /home/lihao/miniconda3/envs/unsloth_upgrade/lib/python3.11/site-packages
Requires: huggingface-hub, numpy, packaging, psutil, pyyaml, safetensors, torch
Required-by: peft, trl, unsloth, unsloth_zoo
训练
在encoder-only模型上测试unsloth
# unsloth_modernbert_imdb.py
from unsloth import FastModel
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
import os
import torch
import torch.nn as nn
from datasets import load_dataset
from transformers import (
TrainingArguments,
Trainer,
DataCollatorWithPadding,
)
import evaluate
import numpy as np
# ----------------- 配置 -----------------
MODEL_NAME = "answerdotai/ModernBERT-base"
OUTPUT_DIR = "./imdb_unsloth_lora"
MAX_SEQ_LENGTH = 512
NUM_LABELS = 2
NUM_EPOCHS = 3
PER_DEVICE_BATCH = 8
GRAD_ACCUM_STEPS = 4
LEARNING_RATE = 2e-5
WEIGHT_DECAY = 0.01
LOGGING_STEPS = 50
EVAL_STEPS = 500
SEED = 3407
USE_FP16 = True
# IMDB 标签映射(用于正确输出和兼容性)
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}
# ----------------- 加载数据 -----------------
raw_datasets = load_dataset("imdb")
full_train_dataset = raw_datasets["train"] # 25000 样本
# 从训练集中划分 7:2:1 (17500 train, 5000 val, 2500 test)
shuffled_train = full_train_dataset.shuffle(seed=SEED)
train_dataset = shuffled_train.select(range(17500)) # 70%
val_dataset = shuffled_train.select(range(17500, 22500)) # 20%
test_dataset = shuffled_train.select(range(22500, 25000)) # 10%
# ----------------- 加载模型和 tokenizer -----------------
# 使用 FastModel 加载带分类头的模型,full_finetuning=True 避免加载冲突
model, tokenizer = FastModel.from_pretrained(
model_name=MODEL_NAME,
max_seq_length=MAX_SEQ_LENGTH,
auto_model=AutoModelForSequenceClassification,
num_labels=NUM_LABELS,
id2label=id2label,
label2id=label2id,
dtype=torch.float16, # 坑
load_in_4bit=False, # 启用 4-bit 量化,节省内存 # 不启用
full_finetuning=True, # 先完整加载,避免 auto_model 冲突
)
# for name, _ in model.named_modules():
# print(name)
# input()
# ----------------- 打印可训练参数函数 -----------------
def print_trainable_parameters(model):
trainable = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable += param.numel()
print(f"Trainable params: {trainable} / {all_param} ({100 * trainable / all_param:.2f}%)")
# ----------------- LoRA 配置(加载后应用) -----------------
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
r=16,
lora_alpha=16,
lora_dropout=0.0,
# target_modules=["query", "key", "value", "dense"], # ModernBERT 注意力层
target_modules=["Wqkv", "Wo", "Wi"], # ModernBERT 注意力层
)
# 应用 LoRA:冻结基模型,只训练适配器
model = get_peft_model(model, lora_config)
print_trainable_parameters(model) # 现在应显示 ~0.5-1% 可训练参数
# ----------------- 数据预处理 -----------------
def preprocess_function(examples):
tokenized = tokenizer(
examples["text"],
truncation=True,
max_length=MAX_SEQ_LENGTH,
padding=False
)
tokenized["labels"] = examples["label"]
return tokenized
# 预处理所有数据集
train_dataset = train_dataset.map(preprocess_function, batched=True, remove_columns=train_dataset.column_names)
val_dataset = val_dataset.map(preprocess_function, batched=True, remove_columns=val_dataset.column_names)
test_dataset = test_dataset.map(preprocess_function, batched=True, remove_columns=test_dataset.column_names)
# ----------------- DataCollator & Metrics -----------------
data_collator = DataCollatorWithPadding(tokenizer)
accuracy = evaluate.load("accuracy")
f1 = evaluate.load("f1")
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
acc = accuracy.compute(predictions=preds, references=labels)["accuracy"]
f1_micro = f1.compute(predictions=preds, references=labels, average="binary")["f1"]
return {"accuracy": acc, "f1": f1_micro}
# ----------------- TrainingArguments -----------------
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
eval_strategy="epoch",
# eval_steps=EVAL_STEPS,
save_strategy="epoch",
# save_steps=EVAL_STEPS,
save_total_limit=1,
num_train_epochs=NUM_EPOCHS,
per_device_train_batch_size=PER_DEVICE_BATCH,
gradient_accumulation_steps=GRAD_ACCUM_STEPS,
learning_rate=LEARNING_RATE,
weight_decay=WEIGHT_DECAY,
logging_steps=LOGGING_STEPS,
fp16=USE_FP16,
bf16=False, # 坑禁用 BF16,避免 AMP 错误
report_to=None,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
seed=SEED,
optim="adamw_torch", # 改为标准 AdamW,避免 8bit 与 FP16 冲突
gradient_checkpointing=True
)
# ----------------- Trainer -----------------
trainer = Trainer(
model=model, # 使用 model(已带 LoRA)
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset, # 使用 val_dataset 进行训练中评估
processing_class=tokenizer, # Unsloth 推荐:使用 processing_class 优化
data_collator=data_collator,
compute_metrics=compute_metrics
)
# ----------------- 开始训练 -----------------
if __name__ == "__main__":
trainer.train()
trainer.save_model(OUTPUT_DIR)
# 使用 test_dataset 进行最终评估
test_results = trainer.evaluate(eval_dataset=test_dataset)
print(f"Test Accuracy: {test_results['eval_accuracy']}")
print(f"Test F1: {test_results['eval_f1']}")
print("训练完成,模型已保存到:", OUTPUT_DIR)
在decoder-only模型上进行多卡训练
值得注意的是,参考官方文档,目前(2025-11-11)的多GPU训练版本为数据并行和模型拆分并行;
本次仅实现为DDP。
启动指令为:
export CUDA_VISIBLE_DEVICES=6,7
accelerate launch --num_processes=2 train.py
训练代码如下:
import os
import torch
from unsloth import FastLanguageModel
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
# ==================================================
# 1. 设置设备和分布式环境
# ==================================================
local_rank = int(os.environ.get("LOCAL_RANK", "0"))
torch.cuda.set_device(local_rank)
device_str = f"cuda:{local_rank}"
print(f"[rank{local_rank}] Loading model to {device_str} ...")
# ==================================================
# 2. 基础配置
# ==================================================
MODEL_NAME = "Qwen/Qwen2.5-3B-Instruct"
OUTPUT_DIR = "./alpaca_unsloth_distributed"
MAX_SEQ_LENGTH = 512
NUM_EPOCHS = 3
PER_DEVICE_BATCH = 8
GRAD_ACCUM_STEPS = 4
LEARNING_RATE = 2e-5
WEIGHT_DECAY = 0.01
LOGGING_STEPS = 50
EVAL_STEPS = 500
SEED = 3407
USE_FP16 = True
# ==================================================
# 3. 加载数据
# ==================================================
raw_datasets = load_dataset("yahma/alpaca-cleaned")
full_train_dataset = raw_datasets["train"]
# 划分数据
total_samples = len(full_train_dataset)
train_size = int(0.7 * total_samples)
val_size = int(0.2 * total_samples)
test_size = total_samples - train_size - val_size
shuffled_train = full_train_dataset.shuffle(seed=SEED)
train_dataset = shuffled_train.select(range(train_size))
val_dataset = shuffled_train.select(range(train_size, train_size + val_size))
test_dataset = shuffled_train.select(range(train_size + val_size, total_samples))
# ==================================================
# 4. 加载模型和 tokenizer
# ==================================================
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=MODEL_NAME,
max_seq_length=MAX_SEQ_LENGTH,
dtype=torch.float16,
load_in_4bit=False,
device_map={"": device_str},
local_files_only=True,
)
# ==================================================
# 5. LoRA 配置
# ==================================================
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0.0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=SEED,
)
def print_trainable_parameters(model):
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
total = sum(p.numel() for p in model.parameters())
print(f"Trainable params: {trainable:,} / {total:,} ({100 * trainable / total:.2f}%)")
print_trainable_parameters(model)
# ==================================================
# 6. 数据预处理函数(核心修正点⚠️)
# ==================================================
EOS_TOKEN = tokenizer.eos_token
alpaca_prompt = """Below is an instruction that describes a task, write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
{output}"""
def formatting_and_tokenizing_func(examples):
texts = []
for instruction, input_, output in zip(examples["instruction"], examples["input"], examples["output"]):
text = alpaca_prompt.format(instruction=instruction, input=input_, output=output) + EOS_TOKEN
texts.append(text)
# ✅ 修正:显式设置 truncation/padding,避免 batch_size mismatch
tokenized = tokenizer(
texts,
max_length=MAX_SEQ_LENGTH,
truncation=True,
padding="max_length",
return_tensors=None,
)
tokenized["labels"] = tokenized["input_ids"].copy() # label 与 input 对齐
return tokenized
train_dataset = train_dataset.map(formatting_and_tokenizing_func, batched=True, remove_columns=train_dataset.column_names)
val_dataset = val_dataset.map(formatting_and_tokenizing_func, batched=True, remove_columns=val_dataset.column_names)
test_dataset = test_dataset.map(formatting_and_tokenizing_func, batched=True, remove_columns=test_dataset.column_names)
# ==================================================
# 7. 训练参数
# ==================================================
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
eval_strategy="steps",
eval_steps=EVAL_STEPS,
save_strategy="steps",
save_steps=EVAL_STEPS,
save_total_limit=1,
num_train_epochs=NUM_EPOCHS,
per_device_train_batch_size=PER_DEVICE_BATCH,
gradient_accumulation_steps=GRAD_ACCUM_STEPS,
learning_rate=LEARNING_RATE,
weight_decay=WEIGHT_DECAY,
logging_steps=LOGGING_STEPS,
fp16=USE_FP16,
report_to=None,
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
seed=SEED,
optim="adamw_torch",
gradient_checkpointing=True,
ddp_find_unused_parameters=False,
)
# ==================================================
# 8. Trainer
# ==================================================
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
max_seq_length=MAX_SEQ_LENGTH,
tokenizer=tokenizer,
packing=False,
)
# ==================================================
# 9. 开始训练
# ==================================================
if __name__ == "__main__":
trainer.train()
trainer.save_model(OUTPUT_DIR)
test_results = trainer.evaluate(eval_dataset=test_dataset)
print(f"✅ Test Loss: {test_results['eval_loss']:.4f}")
print(f"✅ 模型已保存到:{OUTPUT_DIR}")
评估函数如下:
import os
import torch
from unsloth import FastLanguageModel
from datasets import load_dataset
import evaluate # 从 Hugging Face 导入 'evaluate' 库
from tqdm import tqdm
import warnings
# ==================================================
# 1. 依赖配置
# ==================================================
# 确保已安装指标库:
# pip install evaluate sacrebleu rouge_score
warnings.filterwarnings("ignore")
# ==================================================
# 2. 常量(必须与训练脚本匹配)
# ==================================================
MODEL_NAME = "Qwen/Qwen2.5-3B-Instruct"
OUTPUT_DIR = "./alpaca_unsloth_distributed" # 保存模型的目录
OUTPUT_DIR = MODEL_NAME
MAX_SEQ_LENGTH = 512
SEED = 3407
# 评估样本大小(根据需要调整!)
# 将其更改为 len(test_dataset) 以进行完整评估
SAMPLE_SIZE = 100
# ==================================================
# 3. 加载测试数据集(复制拆分逻辑)
# ==================================================
print("加载并拆分数据集...")
raw_datasets = load_dataset("yahma/alpaca-cleaned")
full_train_dataset = raw_datasets["train"]
# 复制确切的拆分
total_samples = len(full_train_dataset)
train_size = int(0.7 * total_samples)
val_size = int(0.2 * total_samples)
test_size = total_samples - train_size - val_size
shuffled_train = full_train_dataset.shuffle(seed=SEED)
# 我们不需要 train/val,只需要 test
test_dataset = shuffled_train.select(range(train_size + val_size, total_samples))
print(f"测试数据集加载完成,包含 {len(test_dataset)} 个示例。")
print(f"使用 {min(SAMPLE_SIZE, len(test_dataset))} 个样本进行评估。")
# ==================================================
# 4. 加载模型和 tokenizer(带适配器)
# ==================================================
print(f"从 '{OUTPUT_DIR}' 加载模型...")
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=OUTPUT_DIR,
max_seq_length=MAX_SEQ_LENGTH,
dtype=torch.float16,
load_in_4bit=False,
device_map="auto",
)
# 为生成配置 pad_token_id
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = tokenizer.pad_token_id
print("模型和 tokenizer 加载完成,准备推理。")
# ==================================================
# 5. 定义推理提示
# ==================================================
# 此提示必须与训练格式匹配,
# 但不包括 '{output}' 部分
alpaca_prompt_inference = """Below is an instruction that describes a task, write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
"""
# ==================================================
# 6. 加载指标
# ==================================================
print("加载 ROUGE 和 SacreBLEU 指标...")
rouge = evaluate.load("rouge")
sacrebleu = evaluate.load("sacrebleu")
# ==================================================
# 7. 评估和生成循环
# ==================================================
predictions = []
references = []
print(f"开始生成 {SAMPLE_SIZE} 个预测...")
# 使用 .select() 获取样本
sample_dataset = test_dataset.select(range(SAMPLE_SIZE))
for example in tqdm(sample_dataset):
prompt = alpaca_prompt_inference.format(
instruction=example["instruction"],
input=example["input"]
)
reference = example["output"]
# 标记化输入
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
input_length = inputs["input_ids"].shape[1]
# 生成文本
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256, # 预期响应长度
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 仅解码生成的令牌(不包括提示)
new_tokens = outputs[0, input_length:]
prediction = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
predictions.append(prediction)
references.append(reference)
print("生成完成。")
# ==================================================
# 8. 计算并显示指标
# ==================================================
print("计算指标...")
# SacreBLEU 期望引用为列表的列表
references_bleu = [[r] for r in references]
# 计算 ROUGE
rouge_results = rouge.compute(predictions=predictions, references=references)
# 计算 SacreBLEU
bleu_results = sacrebleu.compute(predictions=predictions, references=references_bleu)
print("\n========== 评估结果 ==========")
print(f"评估了 {SAMPLE_SIZE} 个示例。")
print("\n--- ROUGE 指标 ---")
print(f"Rouge1: {rouge_results['rouge1'] * 100:.2f}%")
print(f"Rouge2: {rouge_results['rouge2'] * 100:.2f}%")
print(f"RougeL: {rouge_results['rougeL'] * 100:.2f}%")
print(f"RougeLsum: {rouge_results['rougeLsum'] * 100:.2f}%")
print("\n--- SacreBLEU 指标 ---")
print(f"BLEU 分数: {bleu_results['score']:.2f}")
print(f"细节 (1-gram/2-gram/3-gram/4-gram): {bleu_results['counts']}")
# 可选:打印一些预测
print("\n========== 输出示例 ==========")
for i in range(min(5, SAMPLE_SIZE)): # 打印前 5 个
print(f"\n--- 示例 {i+1} ---")
print(f"指令: {sample_dataset[i]['instruction']}")
print(f"输入: {sample_dataset[i]['input']}")
print("-" * 20)
print(f"引用 (黄金标准): {references[i]}")
print(f"预测 (模型): {predictions[i]}")
print("\n✅ 评估完成。")
结果
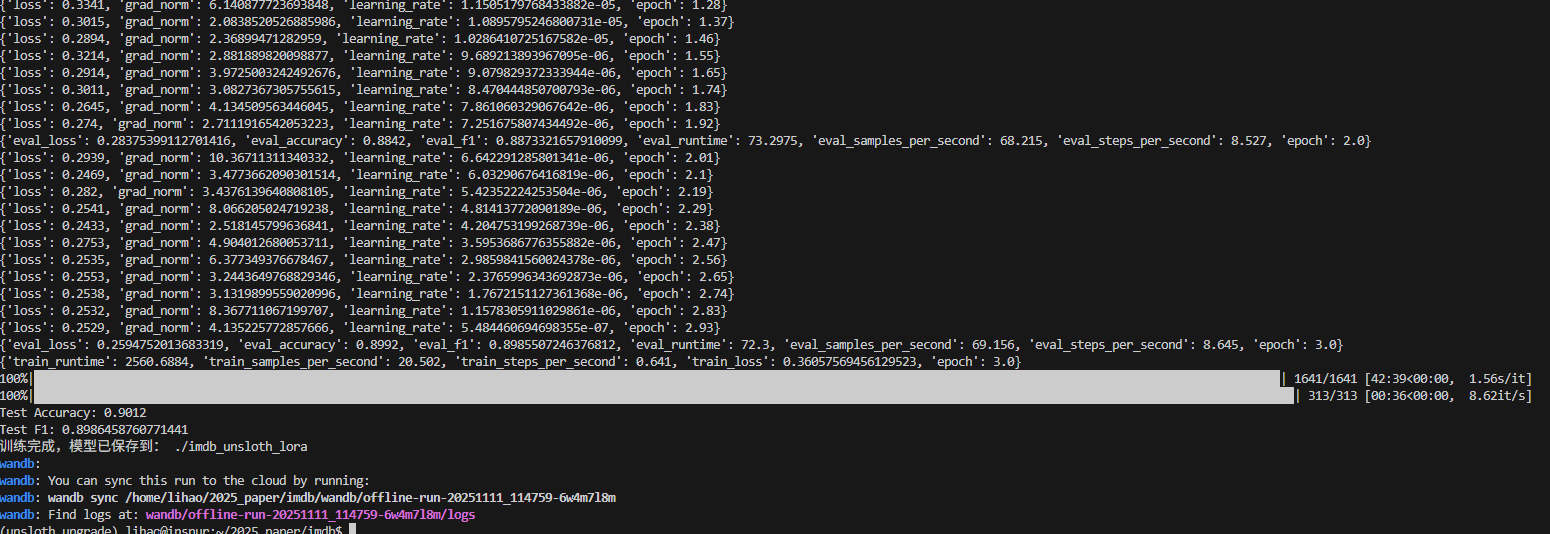
encoder-only在IMDB分类上的结果:
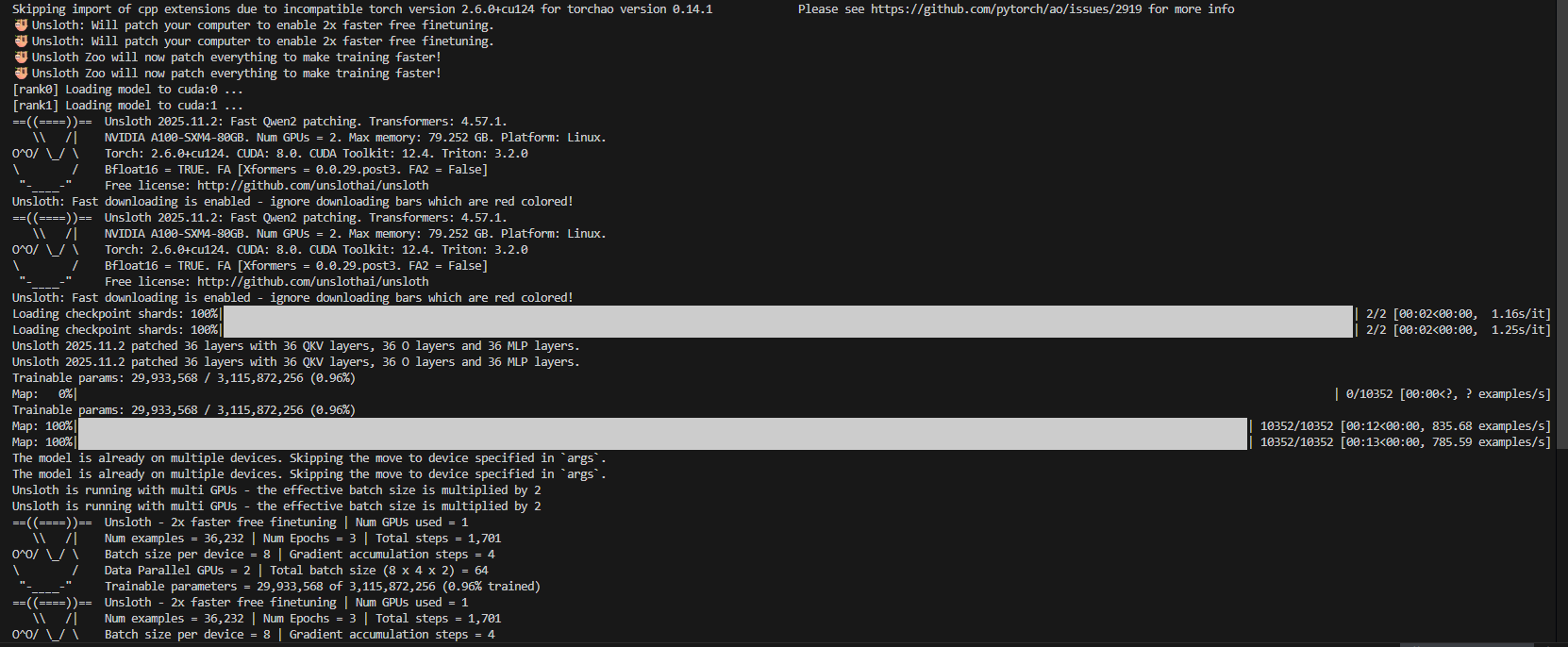
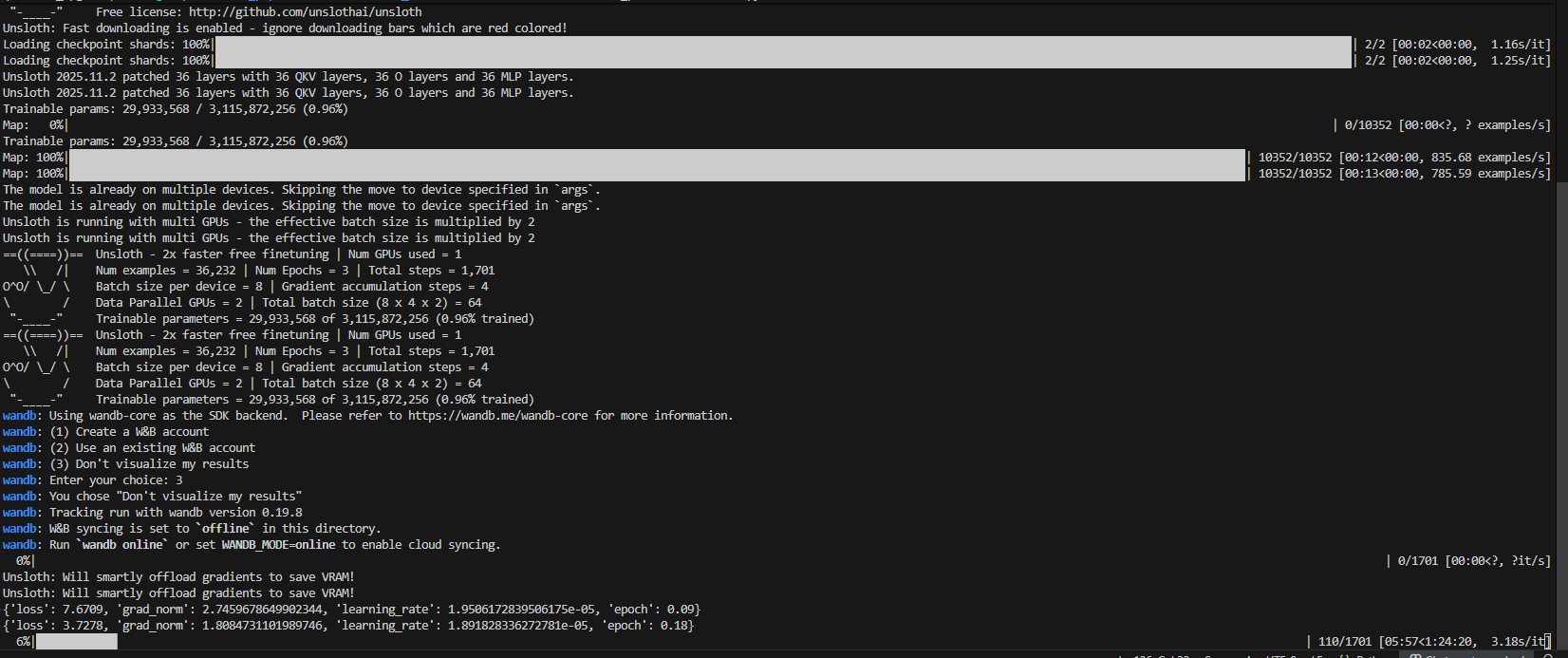
decoder-only在alpaca指令跟随上的结果:
训练过程如图:
训练前后再BLEU和Rouge-L指标上的对比:


总结
- encoder-only的模型也可以使用unsloth进行训练,不过导入模型的设置不同,具体如下:
from unsloth import FastModel
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# 使用 FastModel 加载带分类头的模型,full_finetuning=True 避免加载冲突
model, tokenizer = FastModel.from_pretrained(
model_name=MODEL_NAME,
max_seq_length=MAX_SEQ_LENGTH,
auto_model=AutoModelForSequenceClassification,
num_labels=NUM_LABELS,
id2label=id2label,
label2id=label2id,
dtype=torch.float16, # 坑
load_in_4bit=False, # 启用 4-bit 量化,节省内存 # 不启用
full_finetuning=True, # 先完整加载,避免 auto_model 冲突
)
# 同时注意lora设置的层名称也不一样:
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
r=16,
lora_alpha=16,
lora_dropout=0.0,
# target_modules=["query", "key", "value", "dense"], # ModernBERT 注意力层
target_modules=["Wqkv", "Wo", "Wi"], # ModernBERT 注意力层
)
# training_args中弃用bf16,避免AMP错误:
bf16=False # 坑禁用 BF16,避免 AMP 错误
- 目前(2025-11-11)unsloth的多GPU训练配置依旧比较繁琐,需要自己为每个进程绑定对应 GPU 设备的初始化逻辑:
# 从环境变量 LOCAL_RANK 中读取当前进程在 当前节点(机器)上的 GPU 序号。
# LOCAL_RANK 是 PyTorch 的分布式启动器(例如 torchrun 或 torch.distributed.launch)自动传入的环境变量。根据--num_processes=2 或 --nproc_per_node=4 决定。
local_rank = int(os.environ.get("LOCAL_RANK", "0"))
# 告诉 PyTorch:当前进程默认使用第 local_rank 块 GPU。
torch.cuda.set_device(local_rank)
# 构造一个设备标识字符串,例如 "cuda:0"、"cuda:1",方便打印或传入其他函数使用。
device_str = f"cuda:{local_rank}"
# 打印提示信息,说明当前进程要把模型加载到哪一块 GPU 上。
print(f"[rank{local_rank}] Loading model to {device_str} ...")
- ` ddp_find_unused_parameters=False`:是 Distributed Data Parallel (DDP) 训练中的一个重要参数设置,也是官方推荐的、启用DDP的一个必要措施。