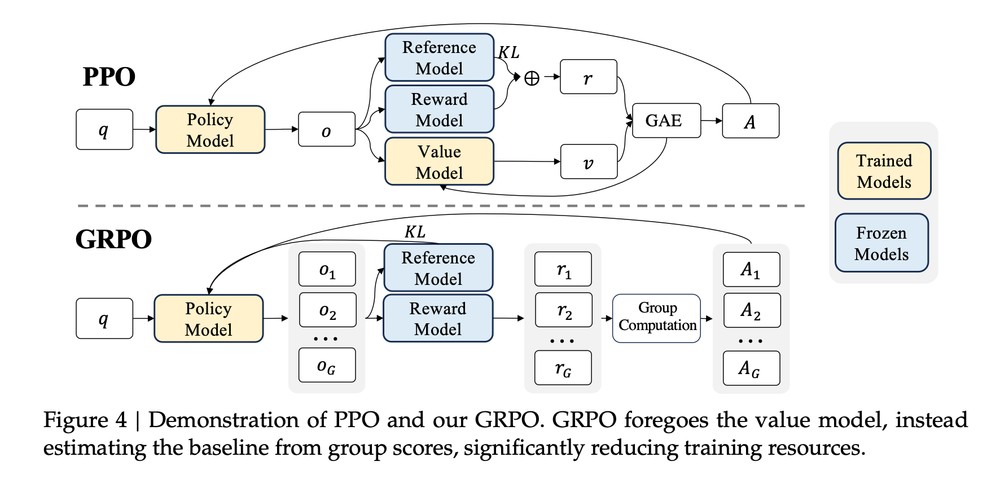
引言
我们以huggingface的accelerate库结合deepspeed为例,采用DP并行的方式,实现对GSM8K的训练。 具体而言:
- DeepSpeed ZeRO 负责 在数据并行维度上分摊参数 / 优化器 / 梯度,实现显存优化与大 batch。
- accelerate 是高层封装器,它会自动帮你生成 deepspeed_config.json 并在 launch 时分配进程、同步梯度、聚合 loss 等。
项目结构如图所示:
环境说明
配置conda环境:
本次实验采用python环境,conda和uv同时管理包依赖:
conda create -n grpo python=3.11 -y
conda activate grpo
pip install uv -U
# CUDA 12.1
uv pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121
# 安装其余依赖
uv pip install transformers datasets accelerate evaluate deepspeed trl bitsandbytes tqdm
# 安装vLLM对推理进行加速
uv pip install vllm
模型选择:
配置网络环境:
# 每次打开新的终端都需要运行
export HF_ENDPOINT=https://hf-mirror.com
# 或写入bash文件
echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
source ~/.bashrc
下载模型(Qwen/Qwen2.5-3B):
hf download Qwen/Qwen2.5-3B --local-dir /home/xx/gsm8k-rl/models/Qwen2.5-3B
配置accelerate
使用下面的命令先默认生成一个default_config.yaml:
python -c "from accelerate.utils import write_basic_config; write_basic_config(mixed_precision='fp16')"
再次执行后,会显示一个路径如下:
Configuration already exists at /home/xx/.cache/huggingface/accelerate/default_config.yaml, will not override. Run `accelerate config` manually or pass a different `save_location`.
默认的yaml如下:
{
"compute_environment": "LOCAL_MACHINE",
"debug": false,
"distributed_type": "MULTI_GPU",
"downcast_bf16": false ,
"enable_cpu_affinity": false,
"machine_rank": 0,
"main_training_function": "main",
"num_machines": 1,
"num_processes": 8,
"rdzv_backend": "static",
"same_network": false,
"tpu_use_cluster": false,
"tpu_use_sudo": false,
"use_cpu": false
}
对上述内容进行修改,我的修改版本如下:
{
"compute_environment": "LOCAL_MACHINE",
"debug": false,
"deepspeed_config":{
"gradient_clipping":1.0,
"zero_stage":2
},
"distributed_type": "DEEPSPEED",
"downcast_bf16": false ,
"enable_cpu_affinity": false,
"machine_rank": 0,
"main_training_function": "main",
"mixed_precision": "no",
"num_machines": 1,
"num_processes": 8,
"rdzv_backend": "static",
"same_network": false,
"tpu_use_cluster": false,
"tpu_use_sudo": false,
"use_cpu": false
}
使用下面的指令对配置结果查看:
accelerate env
使用ds_config.yaml进一步管理,我的ds_config.yaml如下:
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"steps_per_print": 100,
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 3,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9
},
"bf16": {
"enabled": true
},
"activation_checkpointing": {
"partition_activations": false,
"contiguous_memory_optimization": true,
"cpu_checkpointing": false
},
"aio": {
"block_size": 1048576,
"queue_depth": 64,
"single_submit": false,
"overlap_events": true
},
"wall_clock_breakdown": false
}
同时,设置的说明如下:
| 情况 | 使用的配置来源 | 备注 |
|---|---|---|
| 仅 Accelerate 内联配置 | accelerate config 中的 deepspeed_config 字典 |
简单可跑,但功能有限 |
GRPOConfig 指定 deepspeed="ds_config.json" |
指向的 JSON/YAML 文件 | 优先使用文件配置,内联配置不会生效 |
| 两者同时存在 | 文件优先 | 内联配置仅作 fallback / minimal |
注:由于配置文件可能冲突,如果使用ds_config.yaml,最好把原来的”mixed_precision”: “no”移除;
训练
本次训练,采用huggingface的GRPO_trainer进行,数据集选择gsm-8k,结合vLLM进行加速。具体而言,代码如下:
# ----------------------------------with logs + early stopping----------------------------------------
# train_grpo.py
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
from transformers import TrainerCallback
import re
import logging
import os
import numpy as np
# ==========================
# Logging setup
# ==========================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
file_handler = logging.FileHandler('training_details.log')
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(logging.Formatter('%(asctime)s - %(levelname)s - %(message)s'))
logger.addHandler(file_handler)
# ==========================
# Load and preprocess dataset
# ==========================
train_dataset = load_dataset("gsm8k", "main", split="train")
test_dataset = load_dataset("gsm8k", "main", split="test")
def format_gsm8k(example):
prompt = f"Solve the following math problem step by step: {example['question']}\n\nYour answer should be boxed at the end."
example['prompt'] = prompt
example['answer'] = example['answer']
return example
train_dataset = train_dataset.map(format_gsm8k)
test_dataset = test_dataset.map(format_gsm8k)
# ==========================
# Reward Function
# ==========================
def _normalize_answer(s: str) -> str | None:
"""Normalize numeric answers (from GSM8K evaluation rules)."""
if s is None:
return None
s = str(s).strip().replace(",", "")
if s.endswith("."):
s = s[:-1]
try:
num = float(s)
if num.is_integer():
return str(int(num))
return str(num)
except ValueError:
return None
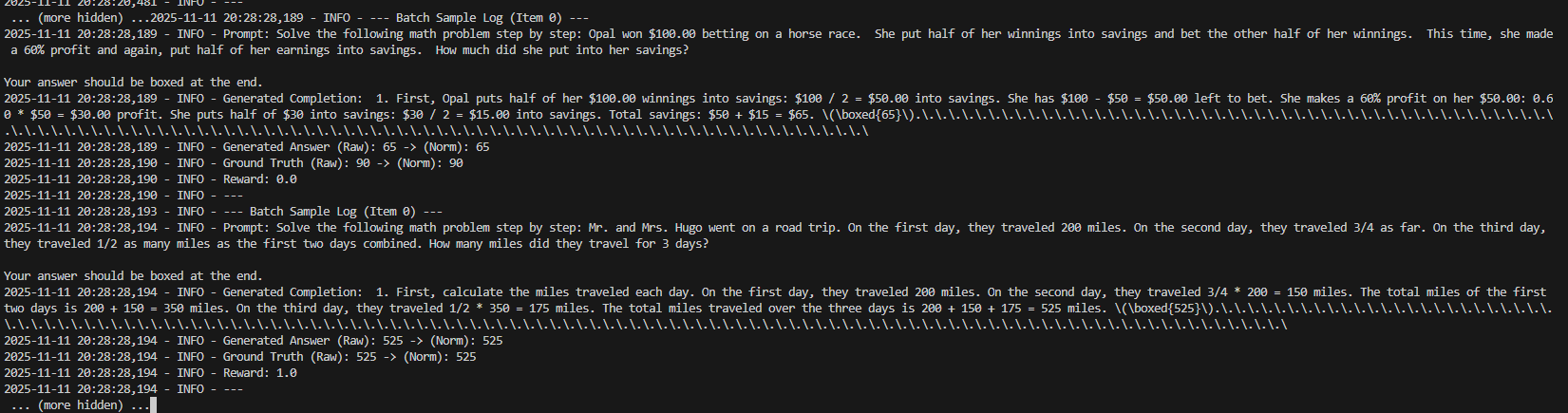
def reward_gsm8k_accuracy(completions, **kwargs):
"""Reward = 1 if model's boxed answer matches ground truth."""
rewards = []
ref_answers = kwargs['answer']
ref_prompts = kwargs['prompts']
gen_answer_regex = r'\\boxed\s*\{\s*([\d\.,]+)\s*\}'
gt_answer_regex = r"####\s*([\d\.,]+)"
for idx, completion in enumerate(completions):
content = completion if isinstance(completion, str) else str(completion)
gen_match = re.findall(gen_answer_regex, content)
gen_answer_str = gen_match[-1] if gen_match else None
gt_match = re.findall(gt_answer_regex, ref_answers[idx])
gt_answer_str = gt_match[-1] if gt_match else None
generated_answer_norm = _normalize_answer(gen_answer_str)
gt_answer_norm = _normalize_answer(gt_answer_str)
reward = 1.0 if (
generated_answer_norm is not None
and gt_answer_norm is not None
and generated_answer_norm == gt_answer_norm
) else 0.0
rewards.append(reward)
if idx == 0:
logger.info(f"--- Batch Sample Log (Item 0) ---")
logger.info(f"Prompt: {ref_prompts[idx]}")
logger.info(f"Generated Completion: {content}")
logger.info(f"Generated Answer (Raw): {gen_answer_str} -> (Norm): {generated_answer_norm}")
logger.info(f"Ground Truth (Raw): {gt_answer_str} -> (Norm): {gt_answer_norm}")
logger.info(f"Reward: {reward}")
logger.info("---")
return rewards
# ==========================
# Custom Callbacks
# ==========================
class LoggingCallback(TrainerCallback):
"""Log training progress every few steps."""
def on_step_end(self, args, state, control, **kwargs):
if state.global_step % 100 == 0:
logger.info(f"Training step {state.global_step} completed.")
def on_evaluate(self, args, state, control, metrics, **kwargs):
logger.info(f"Evaluation metrics: {metrics}")
class EarlyStoppingCallback(TrainerCallback):
"""
Stop training early if eval reward doesn't improve for `patience` evaluations.
"""
def __init__(self, patience=3, metric_key="eval_reward_mean"):
self.patience = patience
self.metric_key = metric_key
self.best_metric = None
self.counter = 0
def on_evaluate(self, args, state, control, metrics, **kwargs):
metric = metrics.get(self.metric_key)
if metric is None:
return
if self.best_metric is None or metric > self.best_metric:
self.best_metric = metric
self.counter = 0
logger.info(f"New best reward {metric:.4f}")
else:
self.counter += 1
logger.info(f"No improvement for {self.counter} eval rounds.")
if self.counter >= self.patience:
logger.info("Early stopping triggered!")
control.should_training_stop = True
# ==========================
# Training Configuration
# ==========================
training_args = GRPOConfig(
output_dir="./Qwen2.5-3B-GRPO-GSM8K",
deepspeed="./ds_config.json",
num_train_epochs=5, # 上限为5;early stopping会提前停止
per_device_train_batch_size=8,
gradient_accumulation_steps=1,
remove_unused_columns=False,
use_vllm=True,
vllm_mode="server",
# ✅ Save config (only keep last checkpoint)
save_strategy="epoch",
save_total_limit=1,
save_only_model=True,
save_safetensors=True,
load_best_model_at_end=False,
# ✅ Evaluation config
eval_strategy="epoch",
logging_strategy="steps",
logging_steps=50,
)
# ==========================
# Trainer
# ==========================
trainer = GRPOTrainer(
model="/home/lihao/gsm8k-rl/models/Qwen2.5-3B",
reward_funcs=[reward_gsm8k_accuracy],
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
callbacks=[LoggingCallback(), EarlyStoppingCallback(patience=2)], # patience=2 表示连续2次无提升则停止
)
# ==========================
# Train
# ==========================
if __name__ == "__main__":
logger.info("Starting GRPO training on GSM8K with early stopping...")
trainer.train()
logger.info("Training finished.")
训练bash如下:
train.bash:
#!/bin/bash
bash vllm.bash
# 等待 vLLM 启动(简单延时,实际可检查日志)
sleep 60 # 调整为模型加载时间(或用 until grep "Serving" vllm.log)
bash acc.bash
acc.bash:
source ~/miniconda3/etc/profile.d/conda.sh && conda activate grpo
# 运行训练(GPU 6,7)
export CUDA_VISIBLE_DEVICES=6,7
accelerate launch --num_processes=2 train.py
vllm.bash:
# 设置环境变量
source ~/miniconda3/etc/profile.d/conda.sh && conda activate grpo
# 启动 vLLM server 在后台(GPU 0)
export CUDA_VISIBLE_DEVICES=5
trl vllm-serve --model /home/lihao/gsm8k-rl/models/Qwen2.5-3B --dtype bfloat16 --tensor-parallel-size 1
结果
vLLM客户端示例:
accelerate端示例:
简单评估结果示例:
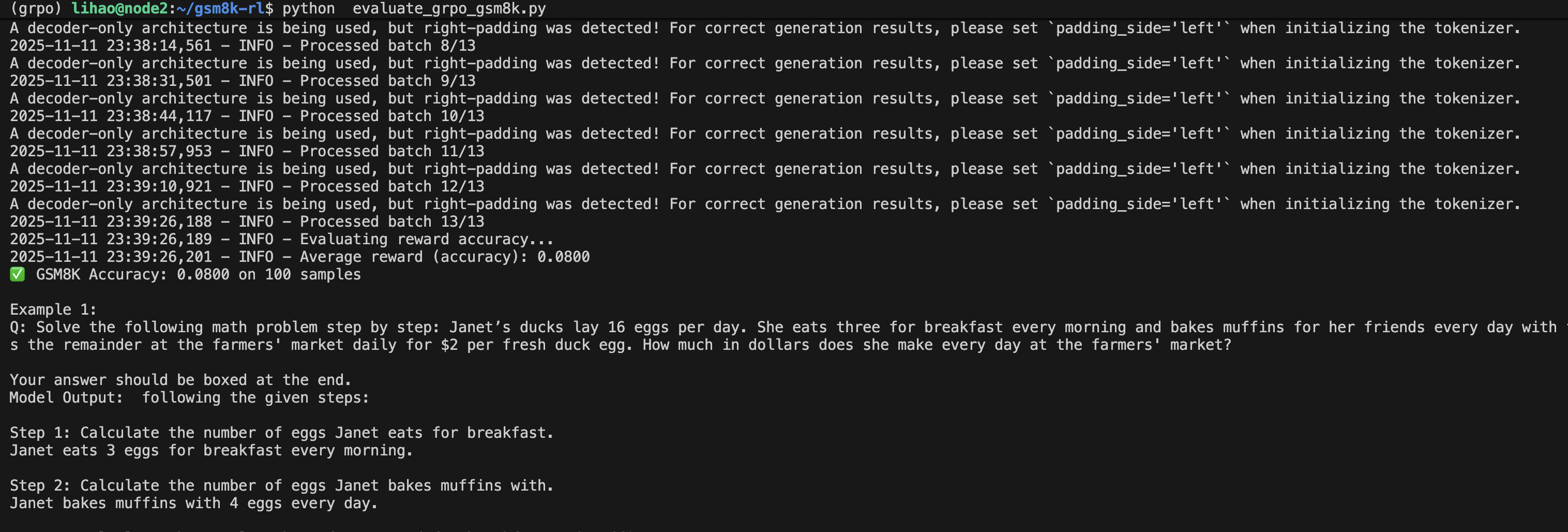
- 下列是qwen2.5-3B在zero-shot下的表现:
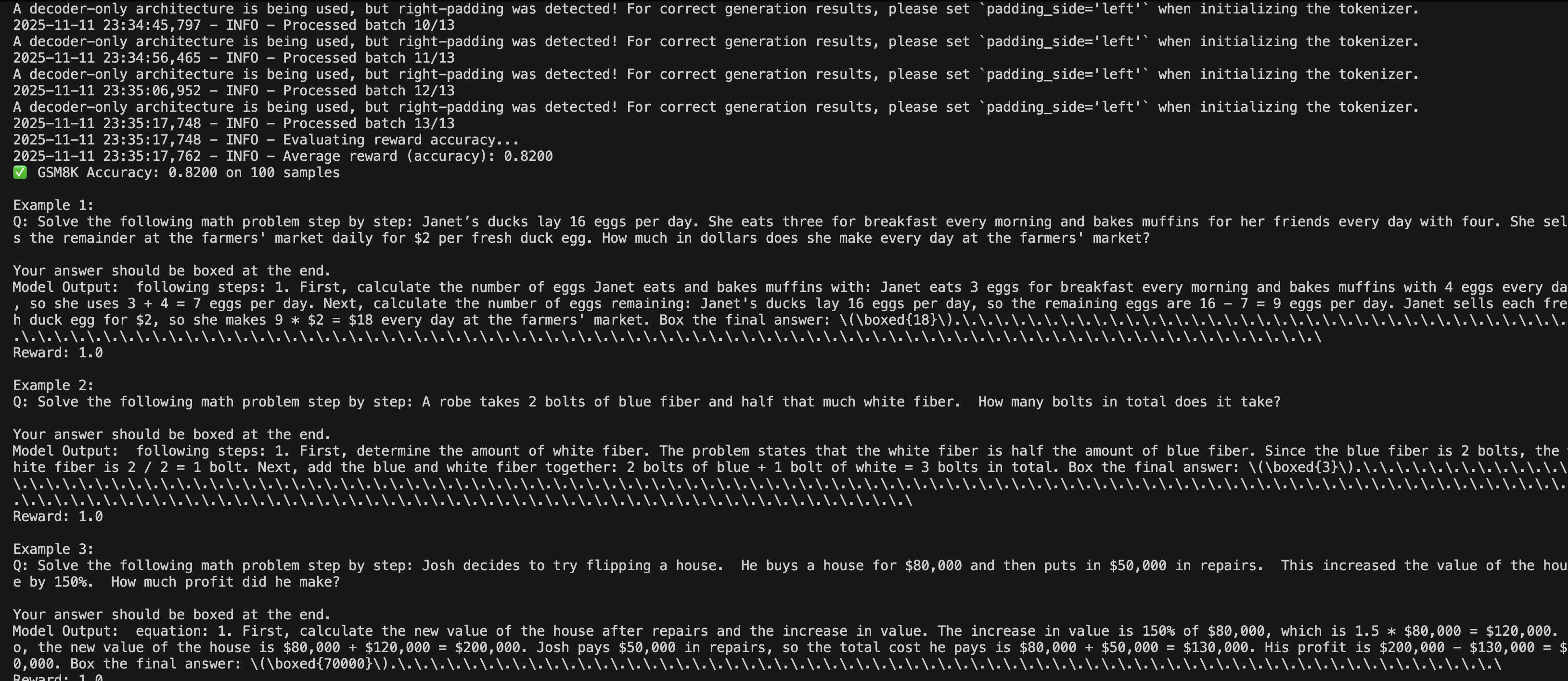
- 下列是qwen2.5-3B在GRPO约12800 steps下的表现:
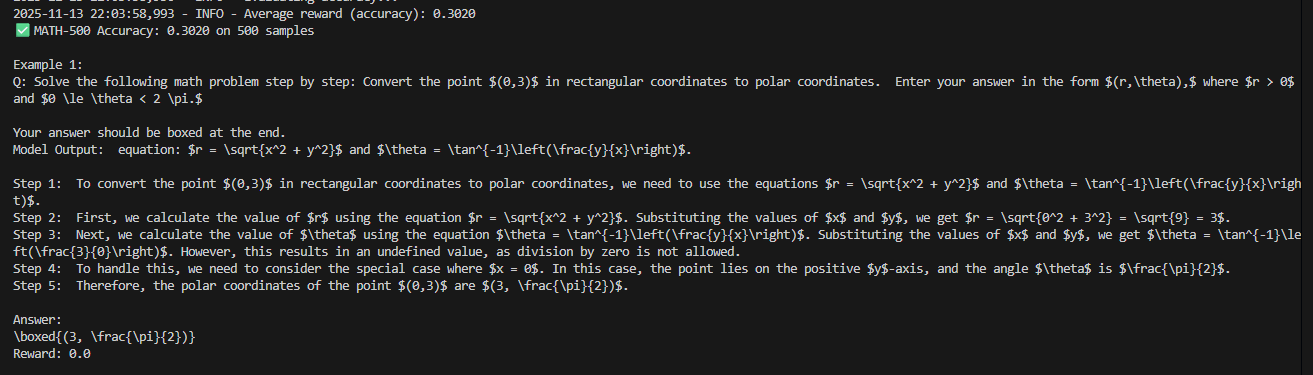
注意到即使在从未训练过的Math500数据集上,也体现出了提升:
- 下列是qwen2.5-3B在Math500数据集中zero-shot下的表现:
- 下列是qwen2.5-3B在GRPO约12800 steps下(on gsm8k)在Math500数据集中的表现:
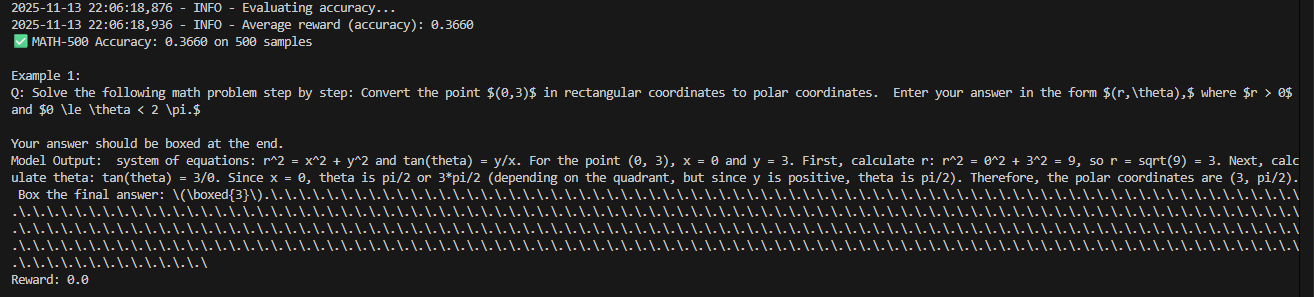
在GRPO的训练中,遇到了下列情况:
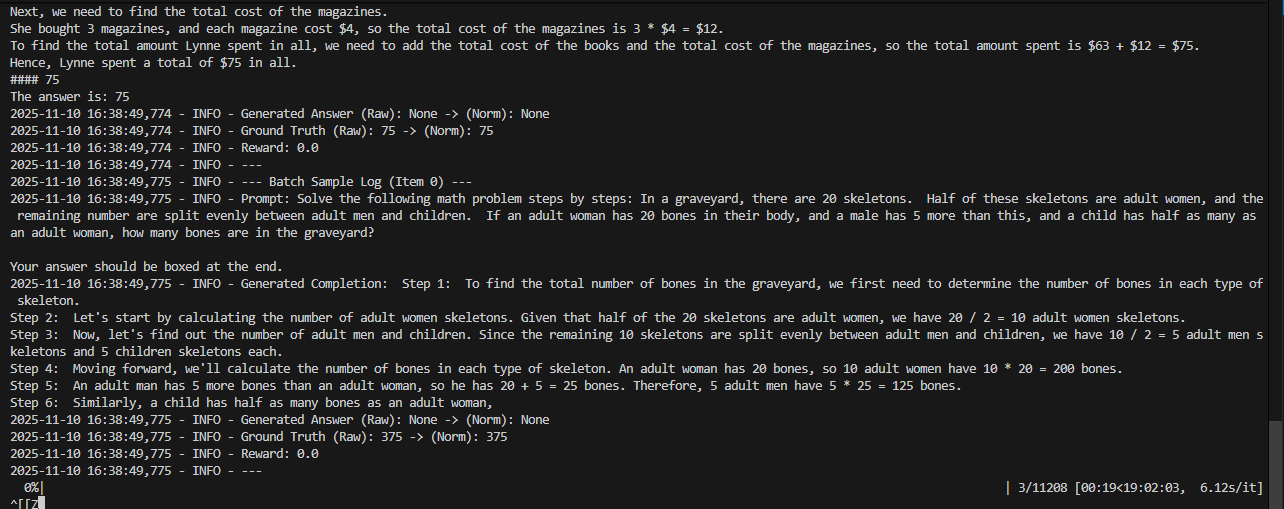
 即出现了 生成的completion里拖着一大串
即出现了 生成的completion里拖着一大串“.”点点点、\.\.\.\.\.之类的多余字符串。 模型输出完 \(\boxed{33}\) 后还觉得自己没“结束”,于是凭语言模型的分布继续生成一些“低信息噪声”,最常见就是句号、空格、\n 或 . 的重复模式。
同时,reward pipeline 比较的是 Generated Answer (Norm) vs Ground Truth (Norm)→ 即,它只看 “33 == 33”,不管生成尾巴多长。没有格式惩罚项(format reward / KL penalty),所以模型可以随意输出。
解决的思路:
trainer = GRPOTrainer(
model=model,
# 在检测到 } 后(即答案闭合),就会提前停止生成。
stop_sequences=["\\boxed{", "}"]
)
总结
可以使用下列指令查看日志中的对应步数:
grep "Training step" training_details.log | tail -n 10
可以使用下列指令合并分布式训练后的模型权重:
python zero_to_fp32.py ./ output
同时,注意合并后只有权重文件,如果需要加载推理还需要将原模型的json文件拷贝进新的目录中;
我的各个库的版本如下:
pip freeze > requirements.txt
Package Version
--------------------------------- ---------------
accelerate 1.11.0
aiohappyeyeballs 2.6.1
aiohttp 3.13.2
aiosignal 1.4.0
annotated-doc 0.0.3
annotated-types 0.7.0
anyio 4.11.0
astor 0.8.1
attrs 25.4.0
bitsandbytes 0.48.2
blake3 1.0.8
cachetools 6.2.1
cbor2 5.7.1
certifi 2025.10.5
cffi 2.0.0
charset-normalizer 3.4.4
click 8.2.1
cloudpickle 3.1.2
compressed-tensors 0.11.0
cupy-cuda12x 13.6.0
datasets 4.4.1
deepspeed 0.17.5+047a7599
depyf 0.19.0
dill 0.4.0
diskcache 5.6.3
distro 1.9.0
dnspython 2.8.0
einops 0.8.1
email-validator 2.3.0
evaluate 0.4.6
fastapi 0.121.1
fastapi-cli 0.0.14
fastapi-cloud-cli 0.3.1
fastrlock 0.8.3
filelock 3.19.1
frozendict 2.4.6
frozenlist 1.8.0
fsspec 2025.9.0
gguf 0.17.1
h11 0.16.0
hf-xet 1.2.0
hjson 3.1.0
httpcore 1.0.9
httptools 0.7.1
httpx 0.28.1
huggingface-hub 0.36.0
idna 3.11
interegular 0.3.3
Jinja2 3.1.6
jiter 0.12.0
jsonschema 4.25.1
jsonschema-specifications 2025.9.1
lark 1.2.2
llguidance 0.7.30
llvmlite 0.44.0
lm-format-enforcer 0.11.3
markdown-it-py 4.0.0
MarkupSafe 2.1.5
mdurl 0.1.2
mistral_common 1.8.5
mpmath 1.3.0
msgpack 1.1.1
msgspec 0.19.0
multidict 6.7.0
multiprocess 0.70.18
networkx 3.5
ninja 1.13.0
numba 0.61.2
numpy 2.2.6
nvidia-cublas-cu12 12.8.4.1
nvidia-cuda-cupti-cu12 12.8.90
nvidia-cuda-nvrtc-cu12 12.8.93
nvidia-cuda-runtime-cu12 12.8.90
nvidia-cudnn-cu12 9.10.2.21
nvidia-cufft-cu12 11.3.3.83
nvidia-cufile-cu12 1.13.1.3
nvidia-curand-cu12 10.3.9.90
nvidia-cusolver-cu12 11.7.3.90
nvidia-cusparse-cu12 12.5.8.93
nvidia-cusparselt-cu12 0.7.1
nvidia-nccl-cu12 2.27.3
nvidia-nvjitlink-cu12 12.8.93
nvidia-nvtx-cu12 12.8.90
openai 2.7.1
openai-harmony 0.0.8
opencv-python-headless 4.12.0.88
outlines_core 0.2.11
packaging 25.0
pandas 2.3.3
partial-json-parser 0.2.1.1.post6
pillow 11.3.0
pip 25.2
prometheus_client 0.23.1
prometheus-fastapi-instrumentator 7.1.0
propcache 0.4.1
protobuf 6.33.0
psutil 7.1.3
py-cpuinfo 9.0.0
pyarrow 22.0.0
pybase64 1.4.2
pycountry 24.6.1
pycparser 2.23
pydantic 2.12.4
pydantic_core 2.41.5
pydantic-extra-types 2.10.6
Pygments 2.19.2
python-dateutil 2.9.0.post0
python-dotenv 1.2.1
python-json-logger 4.0.0
python-multipart 0.0.20
pytz 2025.2
PyYAML 6.0.3
pyzmq 27.1.0
ray 2.51.1
referencing 0.37.0
regex 2025.11.3
requests 2.32.5
rich 14.2.0
rich-toolkit 0.15.1
rignore 0.7.6
rpds-py 0.28.0
safetensors 0.6.2
scipy 1.16.3
sentencepiece 0.2.1
sentry-sdk 2.43.0
setproctitle 1.3.7
setuptools 80.9.0
shellingham 1.5.4
six 1.17.0
sniffio 1.3.1
soundfile 0.13.1
soxr 1.0.0
starlette 0.49.3
sympy 1.14.0
tiktoken 0.12.0
tokenizers 0.22.1
torch 2.8.0
torchaudio 2.8.0
torchvision 0.23.0
tqdm 4.67.1
transformers 4.57.1
triton 3.4.0
trl 0.25.0
typer 0.20.0
typing_extensions 4.15.0
typing-inspection 0.4.2
tzdata 2025.2
urllib3 2.5.0
uv 0.9.8
uvicorn 0.38.0
uvloop 0.22.1
vllm 0.10.2
watchfiles 1.1.1
websockets 15.0.1
wheel 0.45.1
xformers 0.0.32.post1
xgrammar 0.1.23
xxhash 3.6.0
yarl 1.22.0
| 并行维度 | accelerate+deepspeed | Megatron-DeepSpeed |
|---|---|---|
| 数据并行 (DP) | ✅ 支持 | ✅ 支持 |
| ZeRO 优化 | ✅ 支持 | ✅ 支持 |
| Tensor 并行 (TP) | ❌ 不支持 | ✅ 支持 |
| Pipeline 并行 (PP) | ❌ 不支持 | ✅ 支持 |
| 三维并行 (DP+TP+PP) | ❌ 不支持 | ✅ 支持 |