引言
![]()
- minimind旨在从0开始,仅用1.3块钱成本 + 1小时!即可训练出26M参数的超小多模态视觉语言模型MiniMind-V。
- MiniMind-V最小版本体积仅为 GPT3 的约 $\frac{1}{7000}$,力求做到个人GPU也可快速推理甚至训练。
- MiniMind-V是MiniMind纯语言模型的视觉能力额外拓展。
- 项目同时包含了VLM大模型的极简结构、数据集清洗、预训练(Pretrain)、监督微调(SFT)等全过程代码。
- 这不仅是一个开源VLM模型的最小实现,也是入门视觉语言模型的简明教程。
- 希望此项目能为所有人提供一个抛砖引玉的示例,一起感受创造的乐趣!推动更广泛AI社区的进步!
复现过程
1. 环境配置
克隆项目及模型:
# clone项目文件
git clone https://github.com/jingyaogong/minimind-v.git
# 下载clip模型到 ./model/vision_model 目录下
hf download openai/clip-vit-base-patch16 --local-dir /home/lihao/minimind-v/model/vision_model/clip-vit-base-patch16
# 下载minimind语言模型权重到 ./out 目录下(作为训练VLM的基座语言模型)
# HuggingFace
https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch/blob/main/llm_768.pth # or llm_512.pth
创建环境:
conda create -n minimind python=3.11 -y
conda activate minimind
# 使用uv进行包管理
pip install -U uv
uv pip install -r requirements.txt
测试已有模型的效果(使用项目自带的eval_vlm.py):
# 指令的参数解析见eval_vlm.py中main部分
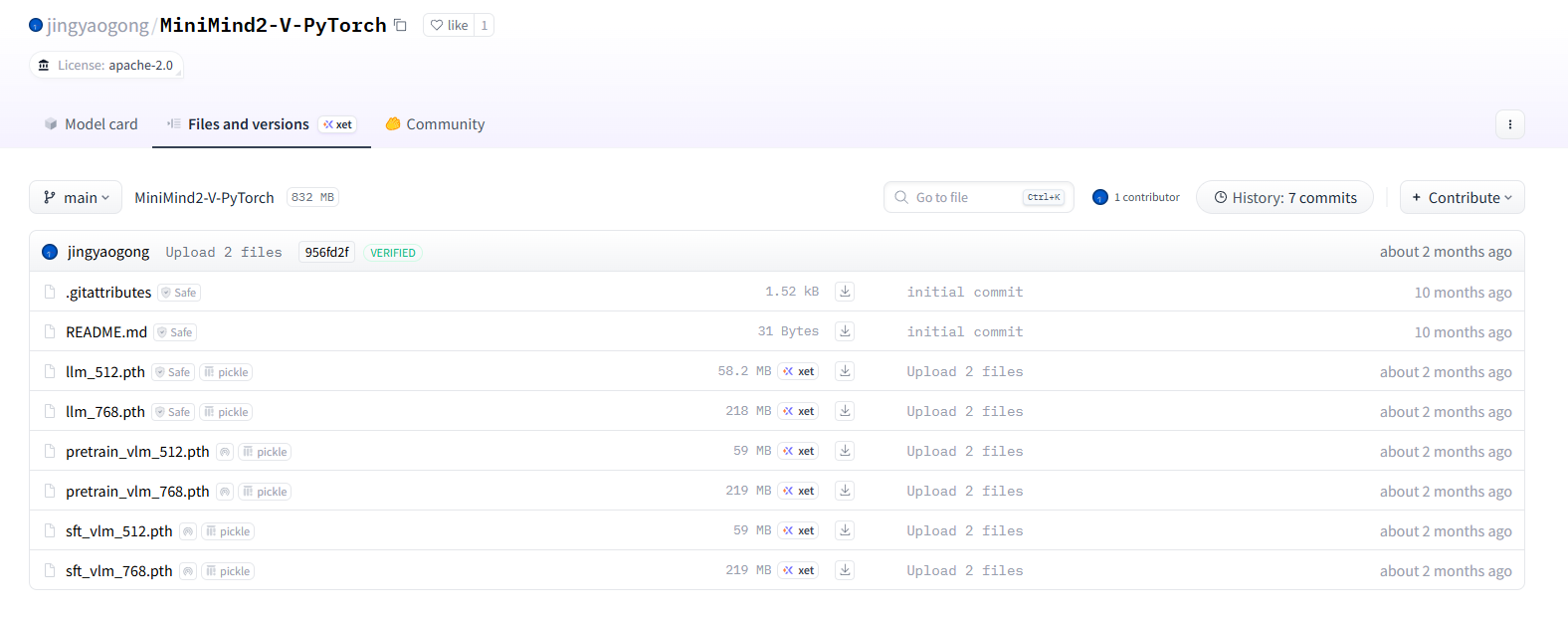
python eval_vlm.py --load_from model --hidden_size 768 --weight llm
效果如下图:
2. 数据准备
# pretrain阶段的数据集
cd ./dataset
wget https://hf-mirror.com/datasets/jingyaogong/minimind-v_dataset/resolve/main/pretrain_data.jsonl
wget https://hf-mirror.com/datasets/jingyaogong/minimind-v_dataset/resolve/main/pretrain_images.zip
unzip pretrain_images.zip && rm pretrain_images.zip
# SFT阶段的数据集
cd ./dataset
wget https://hf-mirror.com/datasets/jingyaogong/minimind-v_dataset/resolve/main/sft_data.jsonl
wget https://hf-mirror.com/datasets/jingyaogong/minimind-v_dataset/resolve/main/sft_images.zip
unzip sft_images.zip && rm sft_images.zip
3. 模型训练
pretrained训练(学习图像描述):
# 注意这步必不可少,否则后续加载tokenizer的路径会有误
cd trainer/
# 基础训练命令(从LLM权重开始,仅训练vision_proj)
python train_pretrain_vlm.py --epochs 4 --from_weight llm --hidden_size 768
# 使用多张GPU进行DDP:
# 设置tmux进行后台训练
tmux new-session -t mm
torchrun --nproc_per_node 2 train_pretrain_vlm.py --epochs 4 --from_weight llm --hidden_size 768 --batch_size 256


测试PT模型的效果(使用项目自带的eval_vlm.py):
# 指令的参数解析见eval_vlm.py中main部分
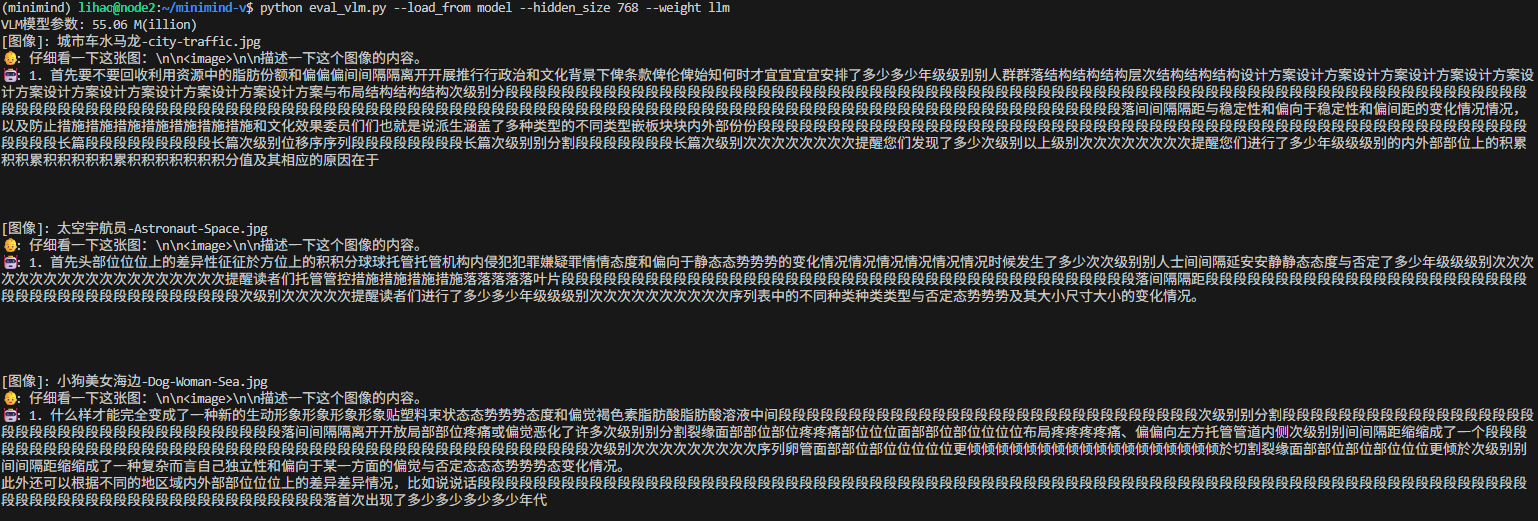
python eval_vlm.py --load_from model --hidden_size 768 --weight pretrain_vlm
效果如图:
SFT训练(学习看图对话):
cd trainer/
# 基础训练命令(从预训练权重开始,全参数微调)
python train_sft_vlm.py --epochs 2 --from_weight pretrain_vlm --hidden_size 768 --batch_size 256
# 使用多张GPU进行DDP:
torchrun --nproc_per_node 2 train_sft_vlm.py --epochs 2 --from_weight pretrain_vlm --hidden_size 768 --batch_size 256
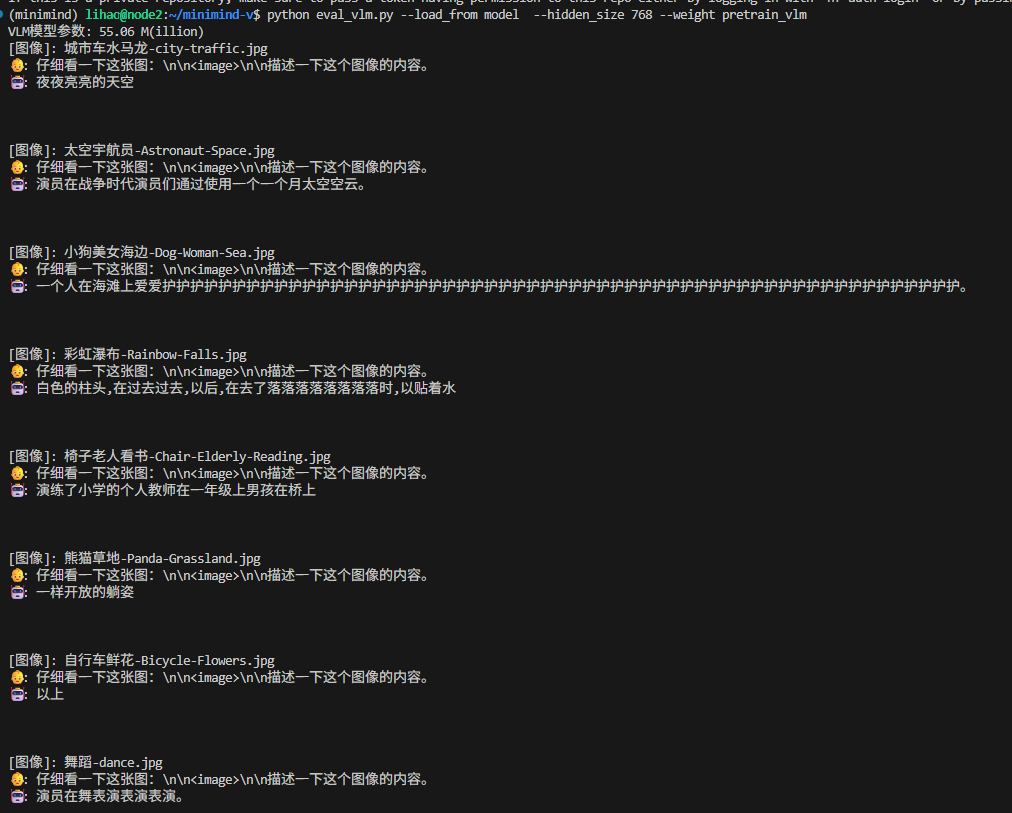
测试SFT模型的效果(使用项目自带的eval_vlm.py):
# 指令的参数解析见eval_vlm.py中main部分
python eval_vlm.py --load_from model --hidden_size 768 --weight sft_vlm
效果如图:
训练代码及模型细节分析
模型结构如下:
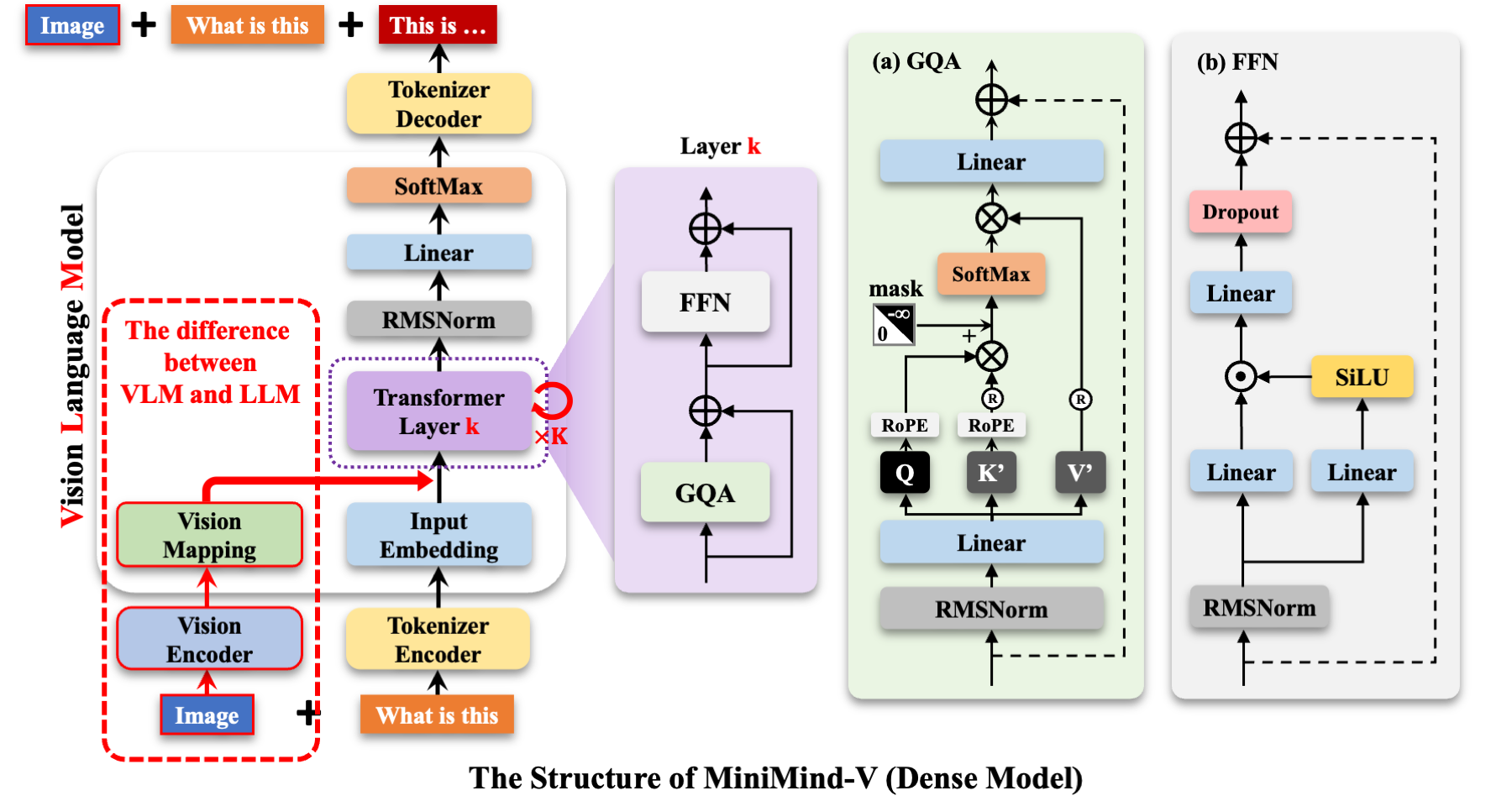
模型输入示例:
VLM的输入依然是一段文本,其中包含特殊的<image>占位符。 在计算文本嵌入后,可以将图像编码器生成的向量投影到该占位符对应的嵌入部分,替换掉原先的占位符embedding。 例如:
<image>\n这个图像中有什么内容?
在minimind-v中,使用196个字符组成的 @@@...@@@ 占位符代替图像,之所以是196个字符,前面有所提及: 任何图像都被clip模型encoder为196×768维的token, 因此minimind-v的prompt为:
@@@......@@@\n这个图片描述的是什么内容?
计算完embedding和projection,并对图像部分token替换后整个计算过程到输出则和LLM部分没有任何区别。
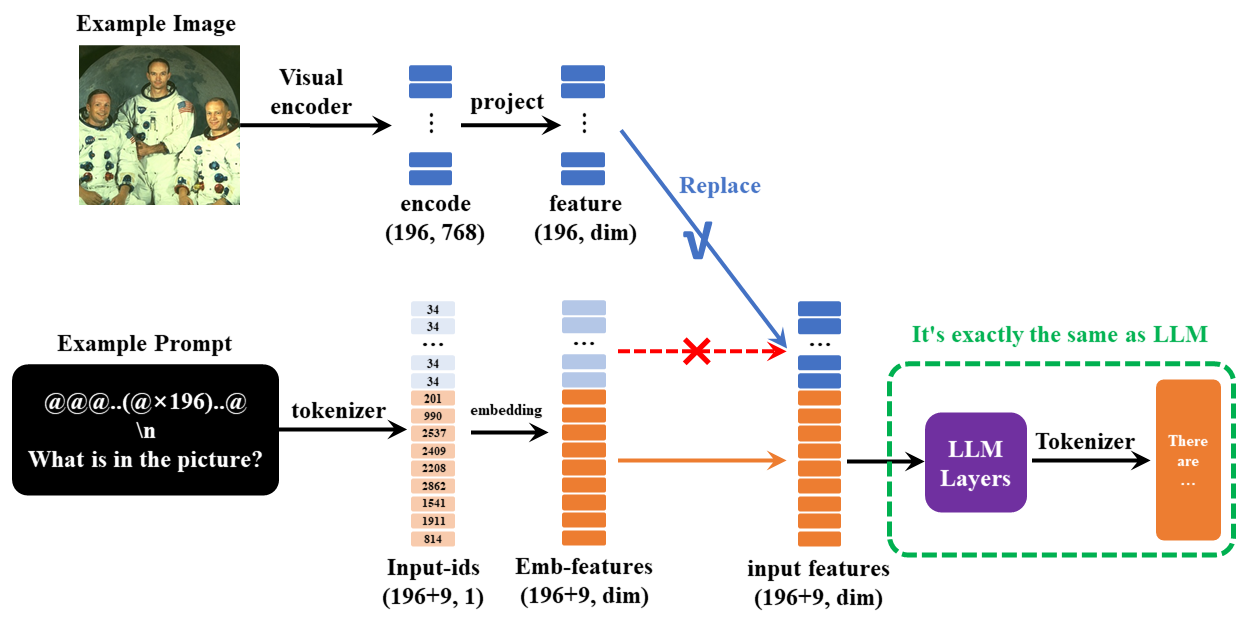
一次性多图的实现方法就是通过注入多个<image>图像占位符进行实现,不需要修改任何框架。
视觉模块分析
训练代码分析
lm_dataset.py:
import json
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import torch
from model.model_vlm import MiniMindVLM
import os
# 关闭 tokenizer 的多线程并行(避免 warning)
os.environ["TOKENIZERS_PARALLELISM"] = "false"
class VLMDataset(Dataset):
def __init__(self, jsonl_path, images_path, tokenizer, preprocess=None, max_length=512,
image_special_token='@' * 196):
super().__init__()
# 加载 jsonl 文件中的所有样本
self.samples = self.load_data(jsonl_path)
# 图像所在目录路径
self.images_path = images_path
# 文本 tokenizer
self.tokenizer = tokenizer
# 最大序列长度
self.max_length = max_length
# 图像预处理函数
self.preprocess = preprocess
# 模型中的图像特殊 token(如 196 个 '@')
self.image_token = image_special_token
# 获取 <|im_start|>assistant 的 token id 序列
self.bos_id = tokenizer('<|im_start|>assistant', add_special_tokens=False).input_ids
# 获取 <|im_end|> 的 token id 序列
self.eos_id = tokenizer('<|im_end|>', add_special_tokens=False).input_ids
def __len__(self):
# 返回样本数量
return len(self.samples)
def load_data(self, path):
# 逐行读取 jsonl 文件
samples = []
with open(path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
data = json.loads(line.strip())
# 将每行 JSON 转为 Python dict
samples.append(data)
return samples
def _create_chat_prompt(self, conversations):
# 将 multi-turn 对话转换成 Chat Template 格式
messages = []
for i, turn in enumerate(conversations):
# 偶数索引:user,奇数索引:assistant
role = 'user' if i % 2 == 0 else 'assistant'
# 将 <image> 替换为模型定义的 image token
messages.append({
"role": role,
"content": turn['content'].replace('<image>', self.image_token)
})
# 使用 tokenizer 的 Chat Template 生成最终 prompt 字符串
return self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
def _generate_loss_mask(self, input_ids):
"""
根据 <|im_start|>assistant ... <|im_end|> 生成 loss mask。
仅在 assistant 的回答部分计算 loss,其余部分 mask=0。
"""
loss_mask = [0] * len(input_ids)
i = 0
while i < len(input_ids):
# 找到 <|im_start|>assistant
if input_ids[i:i + len(self.bos_id)] == self.bos_id:
# assistant 内容的开始位置
start = i + len(self.bos_id)
end = start
# 找到对应的 <|im_end|>
while end < len(input_ids):
if input_ids[end:end + len(self.eos_id)] == self.eos_id:
break
end += 1
# 为 assistant 的回答部分设置 loss mask 为 1
for j in range(start + 1, min(end + len(self.eos_id) + 1, self.max_length)):
loss_mask[j] = 1
# 跳到 end 之后继续
i = end + len(self.eos_id) if end < len(input_ids) else len(input_ids)
else:
i += 1
return loss_mask
def __getitem__(self, index: int):
# 读取样本
sample = self.samples[index]
# 图像路径(可能包含多个,用逗号分隔)
image_paths = sample['image']
# 构造聊天 prompt
prompt = self._create_chat_prompt(sample['conversations'])
# tokenizer 对文本编码,并截断至 max_length
input_ids = self.tokenizer(prompt).input_ids[:self.max_length]
# 不足 max_length 部分进行 padding
input_ids += [self.tokenizer.pad_token_id] * (self.max_length - len(input_ids))
# 为 assistant 的回答部分生成 mask
loss_mask = self._generate_loss_mask(input_ids)
# 构造模型输入 X(去掉最后一个 token)
X = torch.tensor(input_ids[:-1], dtype=torch.long)
# 构造标签 Y(去掉第一个 token)
Y = torch.tensor(input_ids[1:], dtype=torch.long)
# loss mask 同样右移一位
loss_mask = torch.tensor(loss_mask[1:], dtype=torch.long)
# 加载并处理图片
image_tensors = []
for image_name in image_paths.split(','):
image_name = image_name.strip()
# 去除空格
# 打开图片
image = Image.open(f'{self.images_path}/{image_name}')
# 使用模型提供的预处理方法转换为 tensor
image_tensor = MiniMindVLM.image2tensor(image, self.preprocess)
image_tensors.append(image_tensor)
# 堆叠成形如 (num_images, C, H, W)
image_tensors = torch.stack(image_tensors, dim=0)
# 返回(输入、标签、loss mask、图像)
return X, Y, loss_mask, image_tensors
该代码定义了一个用于多模态视觉语言模型(VLM)的 VLMDataset 数据集类,主要功能包括:
- 从 jsonl 文件中读取数据, 每一行包含一个 sample,里面包括:
- 图像路径(可能多个,用逗号分隔)
- conversations(用户/助手对话序列,其中
<image>表示图像位置)
- 将对话格式转换为模型输入字符串
- 用 tokenizer 的 apply_chat_template 方法生成模型能理解的聊天格式文本
- 将
<image>占位符替换成模型规定长度的特征 token('@' * 196)
- 对文本进行 token 化,并构造训练标签
- X 是输入(input_ids 去掉最后一个 token)
- Y 是输出(input_ids 去掉第一个 token)
- 根据
<|im_start|>assistant和<|im_end|>自动计算 loss mask,让模型只学习 assistant 的回答部分
- 加载图像并转成模型输入的 tensor
- 支持多张图片,用
MiniMindVLM.image2tensor转换 - 最终返回:
X, Y, loss_mask, image_tensors供 DataLoader 使用。
model_vlm.py
import os
import torch
import warnings
# 导入 MiniMind 基础语言模型
from .model_minimind import *
from typing import Optional, Tuple, List
from torch import nn
from transformers import CLIPProcessor, CLIPModel
# HuggingFace 的 CLIP 模型
from typing import List
warnings.filterwarnings('ignore')
# 扩展语言模型用于多模态(图像)
class VLMConfig(MiniMindConfig):
model_type = "minimind-v"
# transformers 识别名
def __init__(
self,
image_special_token: str = '@' * 196,
# 用 196 个 '@' 表示一张图像的占位符
image_ids: List = [34] * 196,
# 对应 tokenizer 中的 196 个特殊 token id
**kwargs,
):
self.image_special_token = image_special_token
# 文本中替换 <image> 的特殊 token
self.image_ids = image_ids
# 图像 token 对应的 ID 序列(长度 196)
super().__init__(**kwargs)
# 调用 MiniMindConfig 的初始化
# 把 CLIP 输出降维成 LLM 能接受的维度:CLIP 输出维度 768,MiniMind LLM hidden_size 是 512 → 所以要线性投影。
class VisionProj(nn.Module):
def __init__(self, ve_hidden_size=768, hidden_size=512):
super().__init__()
self.ve_hidden_size = ve_hidden_size
# vision encoder 输出维度
self.hidden_size = hidden_size
# 语言模型 hidden size
self.vision_proj = nn.Sequential(
# 简单的线性层
nn.Linear(self.ve_hidden_size, self.hidden_size)
)
def forward(self, image_encoders):
vision_proj = self.vision_proj(image_encoders)
# 输出形状: [N, 196, hidden]
return vision_proj
# 继承自语言模型:视觉-语言模型主类.继承 MiniMindForCausalLM(语言模型),在其基础上加入图像编码器。
class MiniMindVLM(MiniMindForCausalLM):
config_class = VLMConfig
# 导入 MiniMind 基础语言模型
def __init__(self, params: VLMConfig = None, vision_model_path="./model/vision_model/clip-vit-base-patch16"):
super().__init__(params)
if not params: params = VLMConfig()
# 如果没传 config 就用默认的
self.params = params
# 加载 CLIP 模型与预处理器
self.vision_encoder, self.processor = self.__class__.get_vision_model(vision_model_path)
# 把 vision encoder 的输出映射到 LLM hidden size
self.vision_proj = VisionProj(hidden_size=params.hidden_size)
# 加载 vision model(CLIP)并冻结参数
@staticmethod
def get_vision_model(model_path: str):
from transformers import logging as hf_logging
hf_logging.set_verbosity_error()
if not os.path.exists(model_path):
return None, None
# 加载 CLIP
model = CLIPModel.from_pretrained(model_path)
processor = CLIPProcessor.from_pretrained(model_path)
# 冻结 vision_encoder 的所有参数
for param in model.parameters():
param.requires_grad = False
return model.eval(), processor
# 图像 → pixel_values(CLIP 输入格式)
@staticmethod
def image2tensor(image, processor):
# 去掉透明通道
if image.mode in ['RGBA', 'LA']: image = image.convert('RGB')
inputs = processor(images=image, return_tensors="pt")['pixel_values']
return inputs
# 经过 CLIP 得到图像 embedding
# CLIP vision_model 输出:
# [CLS] token
# 196 patch tokens
# 这里我们 丢掉 CLS(第 0 个),只取 patch embedding(196 个)
@staticmethod
def get_image_embeddings(image_tensors, vision_model):
with torch.no_grad():
# vision 不训练
outputs = vision_model.vision_model(pixel_values=image_tensors)
img_embedding = outputs.last_hidden_state[:, 1:, :].squeeze()
# 去掉 CLS,只保留 196 patch
# 形状: [num_images, 196, 768]
return img_embedding
# 寻找 image token 并替换为图像 embedding
# 这段是整个 VLM 的核心逻辑:把原本 196 个 image special token 替换成 vision encoder 的输出
def count_vision_proj(self, tokens, h, vision_tensors=None, seqlen=512):
def find_indices(tokens, image_ids):
# 找到 input_ids 中连续匹配 image_ids 的地方(即 @@@...@)
image_ids_tensor = torch.tensor(image_ids).to(tokens.device)
len_image_ids = len(image_ids)
if len_image_ids > tokens.size(1):
return None
# unfold 滑动窗口,找到连续长度=196 的片段
tokens_view = tokens.unfold(1, len_image_ids, 1)
matches = (tokens_view == image_ids_tensor).all(dim=2)
# 返回每个 batch 中所有图像占位符起止位置
return {
batch_idx: [(idx.item(), idx.item() + len_image_ids - 1) for idx in
matches[batch_idx].nonzero(as_tuple=True)[0]]
for batch_idx in range(tokens.size(0)) if matches[batch_idx].any()
} or None
image_indices = find_indices(tokens, self.params.image_ids)
# 如果有 vision_tensors 且找到图像位置,就执行替换
if vision_tensors is not None and image_indices:
# 映射到 hidden_size
vision_proj = self.vision_proj(vision_tensors)
if len(vision_proj.shape) == 3:
# 保证 batch 维度齐全
vision_proj = vision_proj.unsqueeze(0)
new_h = []
for i in range(h.size(0)):
if i in image_indices:
h_i = h[i]
img_idx = 0
# 多图像情况,每个图像替换对应 tokens
for start_idx, end_idx in image_indices[i]:
if img_idx < vision_proj.size(1):
# 替换掉 196 个 image_tokens
h_i = torch.cat((h_i[:start_idx], vision_proj[i][img_idx], h_i[end_idx + 1:]), dim=0)[
:seqlen]
img_idx += 1
new_h.append(h_i)
else:
new_h.append(h[i])
return torch.stack(new_h, dim=0)
return h
# forward:语言模型 + vision 特征替换
def forward(self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
logits_to_keep: Union[int, torch.Tensor] = 0,
pixel_values: Optional[torch.FloatTensor] = None,
**args):
batch_size, seq_length = input_ids.shape
if hasattr(past_key_values, 'layers'): past_key_values = None
# past_key_values 数量 = Transformer 层数
past_key_values = past_key_values or [None] * len(self.model.layers)
# KV Cache 已使用的 token 数(推理模式下用)
start_pos = past_key_values[0][0].shape[1] if past_key_values[0] is not None else 0
# 初始嵌入:token embedding + dropout
hidden_states = self.model.dropout(self.model.embed_tokens(input_ids))
# 如果是第一步(start_pos==0),把图像 embedding 注入序列
if pixel_values is not None and start_pos == 0:
if len(pixel_values.shape) == 6:
# 去掉冗余维度
pixel_values = pixel_values.squeeze(2)
bs, num, c, im_h, im_w = pixel_values.shape
# 处理多图像
stack_dim = 1 if bs > 1 else 0
# 逐张图像编码
vision_tensors = torch.stack([
MiniMindVLM.get_image_embeddings(pixel_values[:, i, :, :, :], self.vision_encoder)
for i in range(num)
], dim=stack_dim)
# 替换掉 196 个 image token
hidden_states = self.count_vision_proj(tokens=input_ids, h=hidden_states, vision_tensors=vision_tensors,
seqlen=input_ids.shape[1])
# 位置编码 + Transformer 层计算
position_embeddings = (
self.model.freqs_cos[start_pos:start_pos + seq_length],
self.model.freqs_sin[start_pos:start_pos + seq_length]
)
presents = []
# 逐层 Transformer
for layer_idx, (layer, past_key_value) in enumerate(zip(self.model.layers, past_key_values)):
hidden_states, present = layer(
hidden_states,
position_embeddings,
past_key_value=past_key_value,
use_cache=use_cache,
attention_mask=attention_mask
)
presents.append(present)
hidden_states = self.model.norm(hidden_states)
# 累加所有 MoE 层的负载均衡损失 aux_loss
aux_loss = sum(
layer.mlp.aux_loss
for layer in self.model.layers
if isinstance(layer.mlp, MOEFeedForward)
)
# 输出 logits
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
logits = self.lm_head(hidden_states[:, slice_indices, :])
output = CausalLMOutputWithPast(logits=logits, past_key_values=presents, hidden_states=hidden_states)
output.aux_loss = aux_loss
return output
train_pretrain_vlm.py:
import os
import sys
__package__ = "trainer"
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import argparse
import time
import warnings
import torch
import torch.distributed as dist
# 从contextlib导入nullcontext上下文管理器,作为autocast的回退选项。
from contextlib import nullcontext
from torch import optim, nn
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data import DataLoader, DistributedSampler
from transformers import AutoTokenizer
from model.model_vlm import MiniMindVLM, VLMConfig
# 从本地dataset模块导入自定义VLMDataset类,用于处理视觉语言数据。
from dataset.lm_dataset import VLMDataset
from trainer.trainer_utils import get_lr, Logger, is_main_process, init_distributed_mode, setup_seed, init_vlm_model, vlm_checkpoint, SkipBatchSampler
warnings.filterwarnings('ignore')
# 定义train_epoch函数,用于训练一个epoch,参数包括当前epoch、数据加载器、总迭代次数、起始步数和可选的wandb日志器。
def train_epoch(epoch, loader, iters, start_step=0, wandb=None):
#创建交叉熵损失函数,reduction='none'表示不进行平均或求和,便于后续自定义计算。
loss_fct = nn.CrossEntropyLoss(reduction='none')
start_time = time.time()
for step, (X, Y, loss_mask, pixel_values) in enumerate(loader, start=start_step + 1):
X = X.to(args.device)
Y = Y.to(args.device)
loss_mask = loss_mask.to(args.device)
pixel_values = pixel_values.to(args.device)
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 进入混合精度上下文(如果启用)。
with autocast_ctx:
res = model(X, pixel_values=pixel_values)
loss = loss_fct(
# 将logits展平为(-1, vocab_size)。
res.logits.view(-1, res.logits.size(-1)),
#将Y展平为(-1,)。
Y.view(-1)
# 将损失重塑回Y的形状。
).view(Y.size())
# 应用掩码计算加权平均损失。
loss = (loss * loss_mask).sum() / loss_mask.sum()
loss += res.aux_loss
loss = loss / args.accumulation_steps
# 使用scaler缩放损失并进行反向传播。
scaler.scale(loss).backward()
if (step + 1) % args.accumulation_steps == 0:
# 取消缩放以检查梯度。
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
if step % args.log_interval == 0 or step == iters - 1:
spend_time = time.time() - start_time
current_loss = loss.item() * args.accumulation_steps
current_lr = optimizer.param_groups[-1]['lr']
eta_min = spend_time / (step + 1) * iters // 60 - spend_time // 60
Logger(f'Epoch:[{epoch+1}/{args.epochs}]({step}/{iters}) loss:{current_loss:.6f} lr:{current_lr:.12f} epoch_Time:{eta_min}min:')
if wandb: wandb.log({"loss": current_loss, "lr": current_lr, "epoch_Time": eta_min})
if (step % args.save_interval == 0 or step == iters - 1) and is_main_process():
model.eval()
moe_suffix = '_moe' if vlm_config.use_moe else ''
ckp = f'{args.save_dir}/{args.save_weight}_{vlm_config.hidden_size}{moe_suffix}.pth'
if isinstance(model, torch.nn.parallel.DistributedDataParallel):
state_dict = model.module.state_dict()
else:
state_dict = model.state_dict()
clean_state_dict = {
key: value for key, value in state_dict.items() if not key.startswith('vision_encoder.')
}
clean_state_dict = {k: v.half().cpu() for k, v in clean_state_dict.items()}
# 半精度保存并移到CPU
torch.save(clean_state_dict, ckp)
vlm_checkpoint(vlm_config, weight=args.save_weight, model=model, optimizer=optimizer,
epoch=epoch, step=step, wandb=wandb, save_dir='../checkpoints', scaler=scaler)
model.train()
del state_dict, clean_state_dict
del X, Y, loss_mask, pixel_values, res, loss
torch.cuda.empty_cache()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="MiniMind-V Pretrain")
parser.add_argument("--save_dir", type=str, default="../out", help="模型保存目录")
parser.add_argument('--save_weight', default='pretrain_vlm', type=str, help="保存权重的前缀名")
parser.add_argument("--epochs", type=int, default=4, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=16, help="batch size")
parser.add_argument("--learning_rate", type=float, default=4e-4, help="初始学习率")
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu", help="训练设备")
parser.add_argument("--dtype", type=str, default="bfloat16", help="混合精度类型")
parser.add_argument("--num_workers", type=int, default=8, help="数据加载线程数")
parser.add_argument("--accumulation_steps", type=int, default=1, help="梯度累积步数")
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
parser.add_argument("--log_interval", type=int, default=100, help="日志打印间隔")
parser.add_argument("--save_interval", type=int, default=100, help="模型保存间隔")
parser.add_argument('--hidden_size', default=512, type=int, help="隐藏层维度")
parser.add_argument('--num_hidden_layers', default=8, type=int, help="隐藏层数量")
parser.add_argument('--max_seq_len', default=640, type=int, help="训练的最大截断长度")
parser.add_argument('--use_moe', default=0, type=int, choices=[0, 1], help="是否使用MoE架构(0=否,1=是)")
parser.add_argument("--data_path", type=str, default="../dataset/pretrain_data.jsonl", help="训练数据路径")
parser.add_argument("--images_path", type=str, default="../dataset/pretrain_images", help="训练图像路径")
parser.add_argument('--from_weight', default='llm', type=str, help="基于哪个权重训练,为none则不基于任何权重训练")
parser.add_argument('--from_resume', default=0, type=int, choices=[0, 1], help="是否自动检测&续训(0=否,1=是)")
parser.add_argument('--freeze_llm', default=1, type=int, choices=[0, 1], help="是否冻结LLM参数(0=否,1=是,仅训练vision_proj)")
parser.add_argument("--use_wandb", action="store_true", help="是否使用wandb")
parser.add_argument("--wandb_project", type=str, default="MiniMind-V-Pretrain", help="wandb项目名")
args = parser.parse_args()
# ========== 1. 初始化环境和随机种子 ==========
local_rank = init_distributed_mode()
if dist.is_initialized(): args.device = f"cuda:{local_rank}"
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
# ========== 2. 配置目录、模型参数、检查ckp ==========
os.makedirs(args.save_dir, exist_ok=True)
vlm_config = VLMConfig(hidden_size=args.hidden_size, num_hidden_layers=args.num_hidden_layers,
max_seq_len=args.max_seq_len, use_moe=bool(args.use_moe))
ckp_data = vlm_checkpoint(vlm_config, weight=args.save_weight, save_dir='../checkpoints') if args.from_resume==1 else None
# ========== 3. 设置混合精度 ==========
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
# ========== 4. 配wandb ==========
wandb = None
if args.use_wandb and is_main_process():
import swanlab as wandb
wandb_id = ckp_data.get('wandb_id') if ckp_data else None
resume = 'must' if wandb_id else None
wandb_run_name = f"MiniMind-V-Pretrain-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}"
wandb.init(project=args.wandb_project, name=wandb_run_name, id=wandb_id, resume=resume)
# ========== 5. 定义模型、数据、优化器 ==========
model, tokenizer, preprocess = init_vlm_model(vlm_config, from_weight=args.from_weight,
device=args.device, freeze_llm=bool(args.freeze_llm))
train_ds = VLMDataset(args.data_path, args.images_path, tokenizer, preprocess=preprocess,
image_special_token=vlm_config.image_special_token,
max_length=vlm_config.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == 'float16'))
optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=args.learning_rate)
# ========== 6. 从ckp恢复状态 ==========
start_epoch, start_step = 0, 0
if ckp_data:
model.load_state_dict(ckp_data['model'], strict=False)
optimizer.load_state_dict(ckp_data['optimizer'])
scaler.load_state_dict(ckp_data['scaler'])
start_epoch = ckp_data['epoch']
start_step = ckp_data.get('step', 0)
# ========== 7. DDP包模型 ==========
if dist.is_initialized():
model._ddp_params_and_buffers_to_ignore = {"pos_cis"}
model = DistributedDataParallel(model, device_ids=[local_rank])
# ========== 8. 开始训练 ==========
for epoch in range(start_epoch, args.epochs):
train_sampler and train_sampler.set_epoch(epoch)
if epoch == start_epoch and start_step > 0:
# 第一个epoch且存在检查点
batch_sampler = SkipBatchSampler(train_sampler or range(len(train_ds)), args.batch_size, start_step + 1)
loader = DataLoader(train_ds, batch_sampler=batch_sampler, num_workers=args.num_workers, pin_memory=True)
Logger(f'Epoch [{epoch + 1}/{args.epochs}]: 跳过前{start_step}个step,从step {start_step + 1}开始')
train_epoch(epoch, loader, len(loader) + start_step + 1, start_step, wandb)
else:
# 默认从头开始
loader = DataLoader(train_ds, batch_size=args.batch_size, shuffle=(train_sampler is None), sampler=train_sampler, num_workers=args.num_workers, pin_memory=True)
train_epoch(epoch, loader, len(loader), 0, wandb)
- 基于PyTorch的训练脚本,用于预训练一个名为MiniMindVLM的视觉语言模型(VLM)。它支持分布式训练(使用DistributedDataParallel)、混合精度训练(AMP)、梯度累积和梯度裁剪,以优化内存和训练稳定性。
- 脚本通过命令行参数配置训练设置(如轮数、批大小、学习率),初始化模型和分词器,加载包含文本-图像对的数据集,设置优化器,并在多个epoch中训练模型。训练过程中计算带掩码的交叉熵损失,记录日志,定期保存检查点,并支持从检查点恢复训练。它还可选集成SwanLab(类似于WandB)进行日志记录,并处理MoE(Mixture of Experts)架构选项。
- 模型处理文本和图像输入,如果指定,可冻结LLM部分仅训练视觉投影层。
train_sft_vlm.py
- 基于PyTorch的训练脚本,用于对MiniMindVLM视觉语言模型(VLM)进行监督微调(SFT)。它与预训练脚本类似,支持分布式训练(DistributedDataParallel)、混合精度训练(AMP)、梯度累积和梯度裁剪。脚本通过命令行参数配置训练设置(如轮数减为2、批大小减为4、学习率减为1e-6、最大序列长度增为1536),
- 从预训练权重(from_weight=’pretrain_vlm’)加载模型,不冻结LLM参数(无freeze_llm选项,默认全参数微调),使用不同的数据集路径(sft_data.jsonl和sft_images)。
- 训练过程计算带掩码的交叉熵损失,记录日志,定期保存检查点,并支持从检查点恢复。集成SwanLab进行日志记录,并处理MoE架构选项。整体结构与预训练脚本一致,但专注于SFT阶段的微调。
- 和
train_pretrain_vlm.py共享相同的train_epoch函数实现(包括损失计算、前向传播、梯度更新、日志记录和检查点保存逻辑),没有区别。主要差异集中在命令行参数的默认值、模型初始化和优化器设置上,这些反映了训练阶段的不同需求:PT更注重从LLM权重初始化并冻结部分参数(仅训练视觉投影层),使用更大的批次和学习率,序列长度较短;SFT则从PT权重加载,全参数微调,使用更小的批次和学习率,序列长度更长
trainer_utils.py
"""
训练工具函数集合
"""
import gc
import os
import random
import math
import numpy as np
import torch
import torch.distributed as dist
from torch.utils.data import Sampler
from transformers import AutoTokenizer
from model.model_vlm import MiniMindVLM
def is_main_process():
"""
检查当前进程是否为主进程(rank 0 或非分布式模式)。
"""
return not dist.is_initialized() or dist.get_rank() == 0
def Logger(content):
"""
在主进程中打印日志内容。
"""
if is_main_process():
print(content)
def get_lr(current_step, total_steps, lr):
"""
计算当前步的学习率,使用余弦退火调度器(从 lr/10 渐增到 lr 再渐减)。
"""
return lr / 10 + 0.5 * lr * (1 + math.cos(math.pi * current_step / total_steps))
def init_distributed_mode():
"""
初始化分布式训练模式(如果环境变量设置),返回本地 rank。
"""
if int(os.environ.get("RANK", -1)) == -1:
return 0
# 非DDP模式
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
return local_rank
def setup_seed(seed: int):
"""
设置随机种子,确保训练的可复现性(影响 random、numpy、torch 等)。
"""
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def init_vlm_model(vlm_config, from_weight='pretrain_vlm', tokenizer_path='../model',
vision_model_path='../model/vision_model/clip-vit-base-patch16',
save_dir='../out', device='cuda', freeze_llm=False):
"""
初始化 VLM 模型、分词器和预处理器,从指定权重加载(可选),并可选冻结 LLM 参数。
"""
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
model = MiniMindVLM(vlm_config, vision_model_path=vision_model_path)
if from_weight != 'none':
moe_suffix = '_moe' if vlm_config.use_moe else ''
weight_path = f'{save_dir}/{from_weight}_{vlm_config.hidden_size}{moe_suffix}.pth'
weights = torch.load(weight_path, map_location=device)
model.load_state_dict(weights, strict=False)
# Pretrain阶段:冻结除 vision_proj 外的所有参数
if freeze_llm:
for name, param in model.named_parameters():
if 'vision_proj' not in name:
param.requires_grad = False
# 默认全参训练时的可选配置(已注释)
# # 只解冻注意力机制中的投影层参数
# for name, param in model.model.named_parameters():
# if any(proj in name for proj in ['q_proj', 'k_proj', 'v_proj', 'o_proj']):
# param.requires_grad = True
Logger(f'所加载VLM Model可训练参数:{sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6:.3f} 百万')
preprocess = model.processor
return model.to(device), tokenizer, preprocess
def vlm_checkpoint(vlm_config, weight='pretrain_vlm', model=None, optimizer=None, epoch=0, step=0, wandb=None, save_dir='../checkpoints', **kwargs):
"""
保存或加载 VLM 模型检查点,包括模型、优化器、scaler 等状态(保存时移除 vision_encoder 参数)。
"""
os.makedirs(save_dir, exist_ok=True)
moe_path = '_moe' if vlm_config.use_moe else ''
ckp_path = f'{save_dir}/{weight}_{vlm_config.hidden_size}{moe_path}.pth'
resume_path = f'{save_dir}/{weight}_{vlm_config.hidden_size}{moe_path}_resume.pth'
if model is not None:
from torch.nn.parallel import DistributedDataParallel
state_dict = model.module.state_dict() if isinstance(model, DistributedDataParallel) else model.state_dict()
# 移除vision_encoder参数(不需要保存,因为是预训练的)
clean_state_dict = {k: v for k, v in state_dict.items() if not k.startswith('vision_encoder.')}
ckp_tmp = ckp_path + '.tmp'
torch.save({k: v.half().cpu() for k, v in clean_state_dict.items()}, ckp_tmp)
os.replace(ckp_tmp, ckp_path)
wandb_id = None
if wandb:
if hasattr(wandb, 'get_run'):
run = wandb.get_run()
wandb_id = getattr(run, 'id', None) if run else None
else:
wandb_id = getattr(wandb, 'id', None)
resume_data = {
'model': state_dict,
'optimizer': optimizer.state_dict(),
'epoch': epoch,
'step': step,
'world_size': dist.get_world_size() if dist.is_initialized() else 1,
'wandb_id': wandb_id
}
for key, value in kwargs.items():
if value is not None:
if hasattr(value, 'state_dict'):
if isinstance(value, DistributedDataParallel):
resume_data[key] = value.module.state_dict()
else:
resume_data[key] = value.state_dict()
else:
resume_data[key] = value
resume_tmp = resume_path + '.tmp'
torch.save(resume_data, resume_tmp)
os.replace(resume_tmp, resume_path)
del state_dict, clean_state_dict, resume_data
gc.collect()
torch.cuda.empty_cache()
else:
# 加载模式
if os.path.exists(resume_path):
ckp_data = torch.load(resume_path, map_location='cpu')
saved_ws = ckp_data.get('world_size', 1)
current_ws = dist.get_world_size() if dist.is_initialized() else 1
if saved_ws != current_ws:
ckp_data['step'] = ckp_data['step'] * saved_ws // current_ws
Logger(f'GPU数量变化({saved_ws}→{current_ws}),step已自动转换为{ckp_data["step"]}')
return ckp_data
return None
class SkipBatchSampler(Sampler):
"""
自定义采样器,用于跳过指定数量的批次(用于从检查点恢复训练)。
"""
def __init__(self, sampler, batch_size, skip_batches=0):
self.sampler = sampler
self.batch_size = batch_size
self.skip_batches = skip_batches
def __iter__(self):
batch = []
skipped = 0
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
if skipped < self.skip_batches:
skipped += 1
batch = []
continue
yield batch
batch = []
if len(batch) > 0 and skipped >= self.skip_batches:
yield batch
def __len__(self):
total_batches = (len(self.sampler) + self.batch_size - 1) // self.batch_size
return max(0, total_batches - self.skip_batches)
- 初始化VLM模型;
- 保存VLM模型;
- 自定义采样器,用于跳过指定数量的批次(用于从检查点恢复训练)。
- 分布式模式设置、种子、参数、日志设置;
eval_vlm.py
prompt = "仔细看一下这张图:\n\n<image>\n\n描述一下这个图像的内容。"
# 自动测试image_dir中的所有图像
- 拼接prompt格式如上;
总结
一个关于自回归语言模型的loss计算的分析:
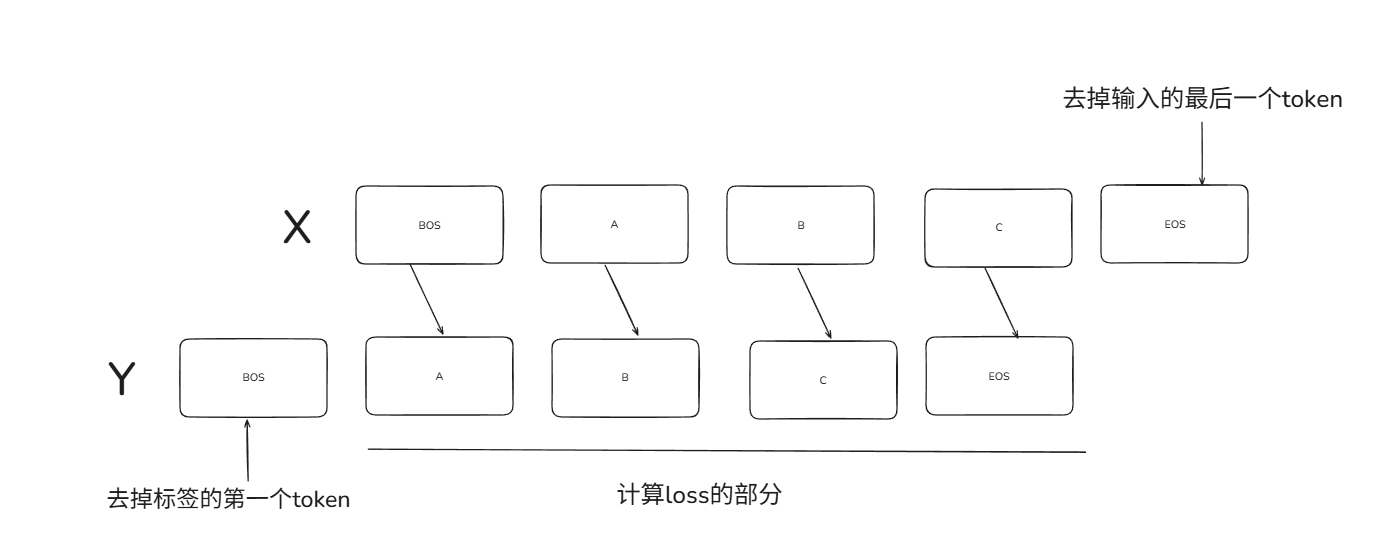
- BOS:取决于 tokenizer(例如,Llama tokenizer 常自动添加 BOS)。如果 prompt 以 BOS 开头,input_ids 会包含它;X 以 BOS 开头,Y 从下一个 token 开始(Y 不包含 BOS 作为第一个,除非特殊配置)。Loss 通常不计算 BOS 的预测(mask=0),因为 BOS 是序列起始符,无需“预测”。
- EOS:如果 prompt 末尾有 EOS(手动添加或 tokenizer 生成),它会出现在 input_ids 末尾;X 不包含 EOS,Y 以 EOS 结尾。Loss 会计算预测 EOS 的位置(如果 mask=1),帮助模型学习结束序列。如果无 EOS,序列可能以 pad 结束,loss_mask 在 pad 上为 0。
- Loss Mask:Mask 也必须和 标签 Y 的长度和位置保持一致。
- 即:
- Y 的第一个 token 的 loss 常被忽略(在标准中,第一个预测基于
[BOS]或空前缀)。 - Y 的最后一个有标签,如果是 EOS,它就是标签。
- 标准实现中,所有 Y 位置都有标签,mask 决定是否计算。
- Y 的第一个 token 的 loss 常被忽略(在标准中,第一个预测基于